Overview
Human language is relatively complex for machine learning and deep learning algorithms to understand. In order to use it for various applications, the human language must be made comprehensible for the machine. Annotation is a critical part of this, where we associate labels to these texts.Data is extremely essential in healthcare and it is one of the fields that use many text data to develop several domain-specific use cases and applications. Functionalities like extracting clinical entities from text, establishing relations, and mapping ICD codes, to name a few, are essential for modern healthcare applications. Machine learning in healthcare has been helping build applications that fulfill these requirements efficiently These texts exist in an unstructured way in clinical notes by physicians, discharge summaries, etc. Sometimes most of the vital information in these notes gets neglected and may sometimes be available in the EHR. To extract these texts and convert them into meaningful information is where the process of clinical data annotation plays an important role.Text mining (TM) techniques can support curators by automatically detecting complex information, such as interactions between drugs, diseases, and adverse effects. This semantic information supports the quick identification of documents containing information of interest.Any general annotation technique trained on available corpora of text data fails to identify and understand several technical and domain-specific jargon in these clinical texts. Spark NLP for healthcare by John Snow labs helps solve this problem by creating several state-of-art techniques whereby they train these annotation models on big medical corpora and use them for standard NLP practices like NER, Question & Answering, Entity resolution, etc. On the other hand, scispaCy uses a full spaCy pipeline and models for scientific/biomedical document annotation. Let's look at them in detail.
John Snow Labs Clinical Annotation
The process of text annotation is multifold. Some of the steps in the process are common for all pipelines, like accumulating raw text into a document, detecting sentences, tokenizing the sentences, and using word embeddings. However, some of the steps are specific to ontological annotation, like extracting information about posology, clinical information, etc. Some of the most common methods are discussed as follows:Currently, Spark NLP supports input texts in the ConLL format to be used in this pipeline. From the raw text in the supported format, the below pipeline follows:Document Assembler: This transforms a text column from a data frame into an Annotation ready for NLP.documentAssembler = DocumentAssembler()
.setInputCol("text")
.setOutputCol("document")Sentence Detector: This step processes various sentences per line. From the document, this extracts each sentence.sentenceDetector = SentenceDetector()
.setInputCols(["document"])
.setOutputCol("sentence")
Tokenizers: The tokenizer, splits words into word tokens which is a relevant format for NLP. The detected sentences are tokenized in this step.tokenizer = Tokenizer()
.setInputCols(["sentence"])
.setOutputCol("token")Word Embeddings: This uses the sentences and tokens and converts them into learned representations of text where words with the same meaning have a similar representation. Below is a snippet of the word embeddings stage where they use a pre-trained model, “embeddings_clinical.” Similarly, they have several other embedding models like BertEmbeddings, BertSentenceEmbeddings, ElmoEmbeddings, inter alia to perform use case-specific tasks.word_embeddings = WordEmbeddingsModel.pretrained("embeddings_clinical", "en", "clinical/models")
.setInputCols(["sentence", "token"])
.setOutputCol("embeddings")Chunkers: Chunkers matches a pattern of part-of-speech tags in order to return meaningful phrases from the document.chunker = Chunker()
.setInputCols(["document", "pos"])
.setOutputCol("chunk") Apart from these basic annotators, there are several other annotator tools used in the Spark NLP pipeline:
- Normalizer: Removes all dirty texts and cleans the text up.
- Stemmer: Returns hard stems out of words with the objective of retrieving the meaningful part of the word
- Lemmatizer: Retrieves lemmas out of words with the objective of returning a base dictionary word.
- Spell/Grammer Checking: Checks for spelling and grammatical errors in the text.
A comprehensive list of other annotators can be found here. One of the first steps of any NLP process is to identify the Entities present in the clinical text. This step is called Clinical Named Entity Recognition. This step uses the sentences and tokens and embeddings to identify the named entities. Example,clinical_ner = NerDLModel.pretrained("ner_clinical_large", "en", "clinical/models")
.setInputCols(["sentence", "token", "embeddings"])
.setOutputCol("ner")Ontology Specific NER: Some of the ontologies on which the Spark NLP models are trained on are as follows:
- General Clinical Ontology: Uses models to extract existing entities of diseases, medical problems, treatments, and medical tests for these problems.
- Posological Ontology: If there are entities related to drugs that are given to the patients, like drug names, dosage, frequency of dosage, duration of dose, etc., this step identifies such entity exists. This can be later used in the entity relation extraction.
- PHI Ontology: Identifying personal information like location, patient name, age, profession, etc. These are later used to mask this sensitive information in the Deidentification step.
The above steps use pre-trained models, which can be used to serve specific purposes. However, we can train custom models, using our preferred dataset to get these entities through the NLP pipeline. Below is an example of the same:nerTagger = NerDLApproach()
.setInputCols(["sentence", "token", "embeddings"])
.setLabelColumn("label")
.setOutputCol("ner")
.setMaxEpochs(2)
.setBatchSize(64)
.setRandomSeed(0)
.setVerbose(1)
.setValidationSplit(0.2)
.setEvaluationLogExtended(True)
.setEnableOutputLogs(True)
.setIncludeConfidence(True)
.setOutputLogsPath('ner_logs')
.setGraphFolder('ner_graph')
.setEnableMemoryOptimizer(True) #>> if you have a limited memory and a large conll file, you can set this True to train batch by batch
#.setTestDataset("NER_NCBIconlltest.parquet")
ner_pipeline = Pipeline(stages=[
clinical_embeddings,
nerTagger
])
Another capability of the Spark NLP healthcare platform is that we can find the Assertion Status. Simply put, assertion status refers to identifying the presence or absence of specific information, like the presence of drug names, disease names, etc. Below is given a sample assertion model for clinical notes.[caption id="attachment_10163" align="aligncenter" width="493"]

A sample assertion model for clinical notes[/caption]Relation Extraction is another annotation process in Spark NLP where we can find out the relationships between two or more entities in the text. It can identify disease-treatment, drug-dosage relationships, temporal relationships(like before after or overlap), etc. The ontological choice between each model we choose depends on the type of problem we are trying to solve. For example, if we try to find out the information between a drug and the frequency in which this drug is given to a patient or in what dosage, we need to use models which will annotate such items in a meaningful way. The following are the different ontological categories of the relation extraction models.[caption id="attachment_10165" align="aligncenter" width="636"]

Ontological categories of the relation extraction models.[/caption]One of the most critical jobs Spark NLP can achieve in this sector is to map the drugs with their normalized codes. All these drug names are normalized in the biomedical world with ICD10 codes and Rx-Norms. Entity resolution will first extract the entity and then map such entities with these normalized codes. For example,[caption id="attachment_10166" align="alignnone" width="711"]

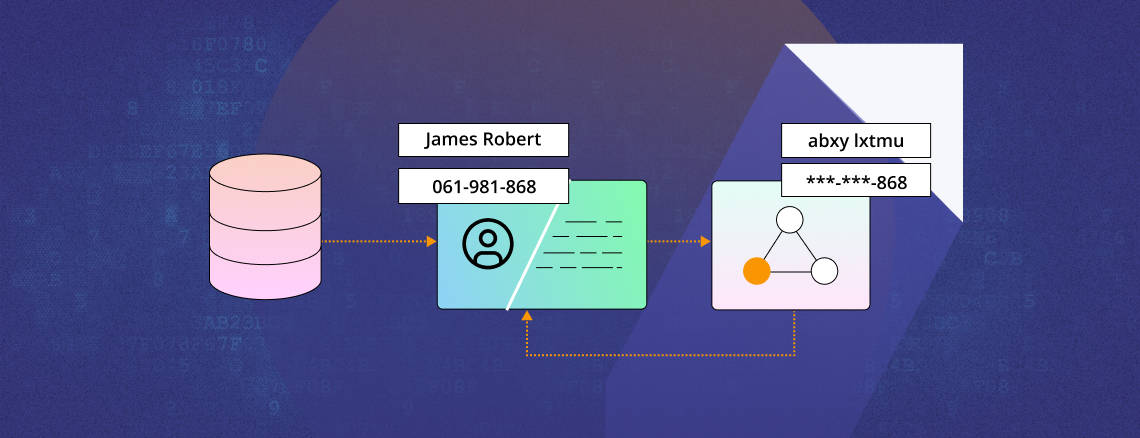
Example of the Relation Extraction process in Spark NLP[/caption]De-Identification of PHI is very important to work in the NLP process so that the secrecy of the personal information is maintained. Here, the personal data from the clinical notes is extracted and then masked. This masked information is reverted, replacing the actual information on the notes.[caption id="attachment_10167" align="aligncenter" width="664"]

De-Identification of PHI[/caption]
scispaCy
Allen AI does similar work as John Snow Labs in this field through scispaCy, by implementing Spcay with scientific and biomedical documents. In particular, there is a custom tokenizer that adds tokenization rules on top of spaCy's rule-based tokenizer, a POS tagger and syntactic parser trained on biomedical data, and an entity span detection model. Separately, there are also NER models for more specific tasks. The models that scispaCy uses for NLP given as below:[caption id="attachment_10168" align="aligncenter" width="674"]

Models that scispaCy uses for NLP[/caption]Abbreviations detecting annotators: Identifies the abbreviations in the clinical notes and finds out the full forms of the same. doc = nlp("Spinal and bulbar muscular atrophy (SBMA) is an
inherited motor neuron disease caused by the expansion
of a polyglutamine tract within the androgen receptor (AR).
SBMA can be caused by this easily.")
print("Abbreviation", "t", "Definition")
for abrv in doc._.abbreviations:
print(f"{abrv} t ({abrv.start}, {abrv.end}) {abrv._.long_form}")
>>> Abbreviation Span Definition
>>> SBMA (33, 34) Spinal and bulbar muscular atrophy
>>> SBMA (6, 7) Spinal and bulbar muscular atrophy
>>> AR (29, 30) androgen receptorEntityLinker: It is a spaCy component that performs linking to a knowledge base. The linker simply performs a string overlap-based search (char-3grams) on named entities, comparing them with the concepts in a knowledge base using an approximate nearest neighbors search.
Conclusion
In today’s world, all industry sectors are using more and more unstructured text data to extract valuable information from a corpus of text and written documents, which is often otherwise ignored. This is used in NLP to serve various cases and business analytics. Healthcare is such a sector that uses a lot of data from clinical documents, discharge summaries, etc., to perform multiple healthcare domain-specific NLP use cases. In this area, John Snow Labs has contributed significantly with Spark NLP for healthcare data scientists. From raw text to ontology-specific text annotation, it can perform many functions in the pipeline, and the functions are fairly extensive. On the other hand, scispaCy, uses spaCy, an NLP library, to serve a similar purpose with Spacy pipeline to do text mining and end to end annotation on unstructured biomedical data to extract meaningful information.







.png)


.png)


.webp)