
How Ideas2IT Rebuilt a KLAS-Recognized Population Health Platform on FHIR, Cut Onboarding from Four Months to Two Weeks, and Halved Infrastructure Costs
HealthEC's population health platform managed 8M+ members across 250+ EMR connections. The architecture holding it together was a per-client deployment model with no FHIR compliance, no cloud portability, and onboarding cycles that took months. Ideas2IT rebuilt the data infrastructure, the ingestion pipeline, and the analytics layer on a FHIR-native, cloud-agnostic architecture.

Client
HealthEC

Industry
Healthcare

Service
App Modernization

Recognition
KLAS Recognized (2019 and 2022)

Members
8M+
01 Challenge
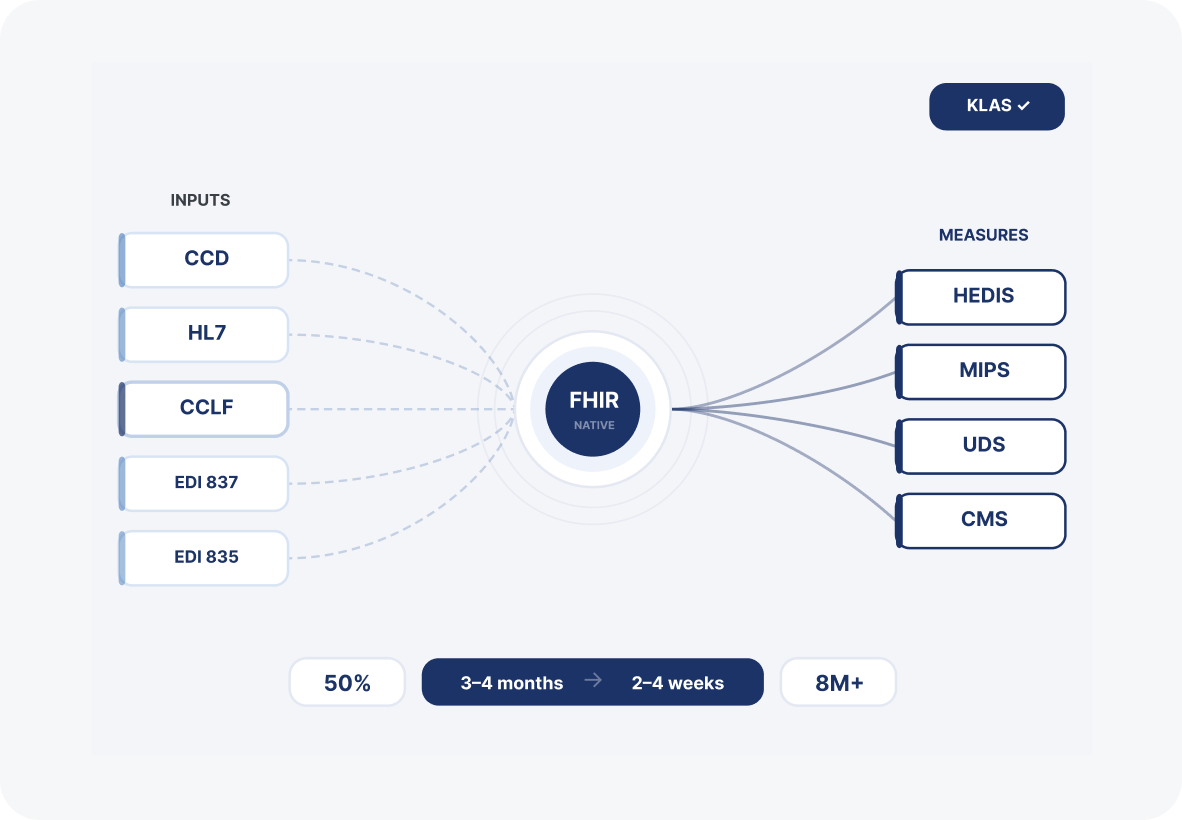
HealthEC's platform ran on a per-client deployment model with data scattered across custom tables in CCD, HL7, EDI 837, EDI 835, and custom-delimited formats. New client onboarding required extensive infrastructure setup and took three to four months. There was no FHIR compliance, no automated data quality layer, and no cloud portability across providers.
02 Solution
Ideas2IT rebuilt the platform on a Kubernetes-based, cloud-agnostic architecture with a FHIR-native data layer at its core. Clinical and claims data in CCD, HL7, CCLF, and EDI formats are converted to FHIR bundles through an in-house transformation pipeline, stored in a Delta Lakehouse using Medallion architecture, and processed through a CQL engine that calculates UDS, MIPS, HEDIS, and CMS quality measures in near real time.
03 Outcome
Operational cost per client dropped 50%. Client onboarding fell from three to four months to two to four weeks. Patient search response times improved 60 to 80%. The platform now manages healthcare data in FHIR format across a multi-tenant, cloud-agnostic architecture built to scale with HealthEC's enterprise customer base.
Phase 01
From per-client on-prem deployment to a shared, FHIR-compliant cloud architecture
FHIR Data Infrastructure and Cloud-Native Migration: replacing fragmented custom tables with a governed, cloud-agnostic data layer
The first problem was the data layer. HealthEC's platform stored patient records in custom tables tied to source format, which meant a CCD file and an HL7 file representing the same clinical event lived in different schemas with no unified representation.
Ideas2IT built a FHIR-native ingestion pipeline that converts every inbound format into standardized FHIR bundles. Clinical and claims files are transferred to S3 via SFTP, where an S3 event triggers the ingestion pipeline.
An in-house Python FHIR Transformer package handles conversion across CCD, HL7, CCLF, EDI 837, and EDI 835 formats. Golang-based platform microservices process and upload the resulting FHIR bundles. All services run on Kubernetes, making the platform deployable across AWS, Azure, or any cloud provider without refactoring.
DELIVERABLES
- FHIR ingestion pipeline covering CCD, HL7, CCLF, EDI 837/835
- In-house FHIR Transformer Python package
- In-house FHIR Client Python package
- Omniparser for multi-format JSON conversion
- S3 SFTP transfer layer
- Kubernetes-based cloud-agnostic deployment
- Multi-tenant architecture
Phase 02
Building the analytics pipeline that runs HEDIS, MIPS, and CMS measures on live FHIR data
Delta Lakehouse, CQL Measure Engine, and Data Quality Layer: turning FHIR bundles into auditable quality measure outputs
With FHIR-standardized data in place, the analytics layer needed to compute population health quality measures at scale without burdening the transactional system. Ideas2IT implemented a Medallion architecture using open-source Delta tables as the cost-efficient storage layer.
An Airflow-orchestrated analytical pipeline consumes Kafka audit events posted by platform microservices, processes them through PySpark, and stores results in a Delta Lakehouse. A CQL engine runs directly on the FHIR data models to calculate UDS, MIPS, HEDIS, and CMS quality measures.
Power BI refreshes dashboards via Trino for near real-time reporting through the HealthEC portal. Great Expectations runs automated data quality checks during stage loading and sends notifications for any data contract violations, replacing the manual validation and reconciliation that had been a persistent operational cost.
DELIVERABLES
- Delta Lakehouse on Medallion architecture
- Airflow-orchestrated analytical pipeline
- CQL measure calculation engine (UDS, MIPS, HEDIS, CMS)
- Kafka audit event layer
- PySpark processing layer
- Great Expectations data quality checks
- Real-time data contract violation notifications
- Power BI dashboards via Trino
Phase 03
Fixing the performance bottlenecks that degraded clinician experience at scale
Patient Search Optimization and Portal UX Rebuild: cutting query latency from 15 minutes to seconds across concurrent clinical users
The PHM portal's patient search ran on stored procedures that queried the database directly, producing response times of five to fifteen minutes under concurrent load.
Ideas2IT optimized the underlying stored procedure through a series of targeted changes: eligible patient IDs were identified earlier while redundant fields in intermediate tables were removed, general patient filters were applied before processing physician and care provider associations, field casting was corrected before filter application, and composite indexes were added to the search path.
Clustered indexes and unnecessary joins were eliminated from intermediate tables. Response times improved 60 to 80% across concurrent user loads. The portal interface was rebuilt from the PowerBI-embedded screens that had produced confusing navigation, using design sprints and prototype-based user testing to generate new user flows before finalizing the UI.
DELIVERABLES
- Optimized patient search stored procedure
- Composite index additions
- Redesigned portal UI/UX
- New user flow architecture from design sprint and user testing
- React-based frontend rebuild
The Outcome
From four-month onboarding cycles and fragmented data to a FHIR-native platform at enterprise scale
The 50% cost reduction and the collapse of a four-month onboarding cycle into weeks were architectural consequences, not optimizations layered on top of the existing system. The per-client deployment model was the cost driver and the onboarding bottleneck. Replacing it with a multi-tenant, Kubernetes-based architecture removed both. The FHIR-native data layer, converting CCD, HL7, and EDI formats at ingestion, was what made the Delta Lakehouse and the CQL measure engine possible. Each layer depended on the decision made in the layer before it. That is what the outcomes reflect.