
Eliminating Manual Reporting: The Data Platform Built for a Multi-Program Behavioral Health Operator
A behavioral health operator running programs across detox, residential care, day treatment, and outpatient needed one platform for HR, finance, recruitment, and operations data. Manual collection from fragmented sources consumed hours per cycle. Azure Data Factory and Power BI changed the ratio.

Client
Behavioral health operator

Industry
Healthcare

Service
Data Modernization

Engagement
Active

Platform
Azure Data Factory · Power BI
01 Challenge
A multi-program behavioral health operator was collecting HR, finance, recruitment, and operations data manually from systems that shared no common format and no common identifiers. Reports took hours to produce, contained inconsistencies, and offered no filtering or historical retention.
02 Solution
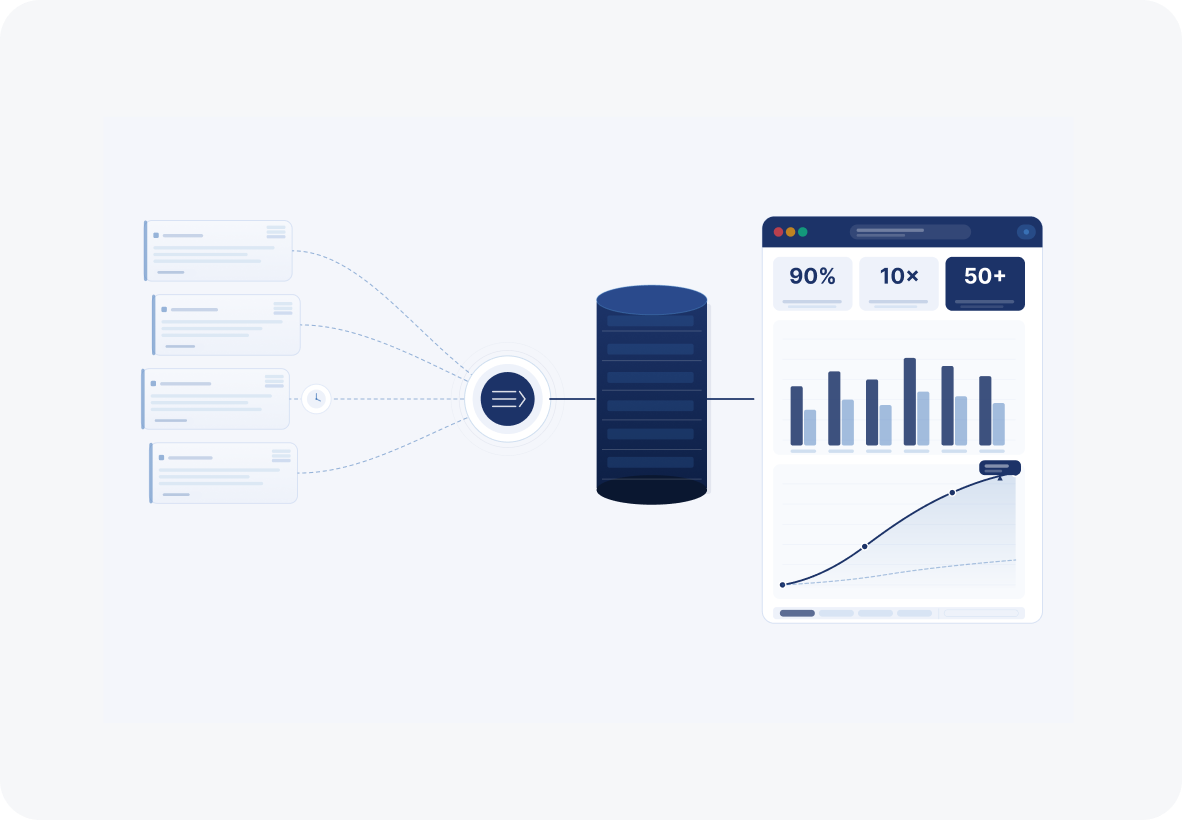
Ideas2IT built a unified data platform on Azure: Data Factory automated ingestion and transformation across every source system, a central Azure Data Warehouse gave all functions a single repository, and Power BI dashboards put real-time, filterable reporting in front of operators who had previously been stitching spreadsheets together by hand.
03 Outcome
Report generation time dropped 90%. The platform now handles 10× the data volume without schema changes breaking pipelines. Fifty-plus KPIs surface as live charts across HR, finance, recruitment, and operations in a single dashboard environment.
Phase 01
Building the Unified Data Hub: Azure Data Factory as the ingestion and transformation spine
The first engineering decision was where to establish the canonical data store. The client's reporting problems were downstream of a more fundamental one:
- HR, finance, recruitment, and operations each lived in separate systems with no shared identifiers and no shared format.
- Azure Data Warehouse was set as the centralized repository before any pipeline was built.
- Azure Data Factory then automated data movement and transformation across every source, creating unique identifiers to relate records between systems.
Horizontal scalability was built into the architecture from the start, so schema changes in any upstream system would require configuration. The platform could absorb new sources without proportional engineering cost.
This Phase Produced
- Azure Data Warehouse (centralized repository)
- Azure Data Factory ingestion pipeline
- Cross-system unique identifier layer
- Automated data transformation engine
- Horizontal scalability architecture
- Schema-change-tolerant data model
Phase 02
Power BI reporting layer: 50+ KPIs surfaced in real time, with filtering that replaced manual extraction
With the data warehouse established and pipelines running, the reporting layer could be built on a foundation that was already consistent.
Power BI was deployed as the visualization layer:
- This meant campaign rules, tier thresholds, and point allocation logic could be updated by configuring rules rather than releasing code.
- The workflow layer handled approvals and notifications at each step of the loyalty lifecycle, giving campaign operations teams visibility and control without touching engineering.
- The final component was the feedback loop: campaign performance results fed back into the analytics engine, so each campaign cycle produced data that tuned the next one. Redis handled session and cache management to keep response times consistent across the platform under concurrent campaign load.
This Phase Produced
- Power BI dashboard suite
- Greenhouse dashboard (initial deployment)
- Real-time KPI visualization layer
- Flexible multi-dimension filtering
- Automated report generation pipeline
- Historical report storage and retrieval
The Outcome
90% less reporting time. One platform. Every business function on the same data.
The 90% reduction in reporting time was the consequence of removing the manual step entirely, not of optimizing it. Azure Data Factory automated what had been a human-carried process. Power BI replaced the formatting cycle. The platform's scalability was architectural: schema changes in upstream systems and a tenfold growth in data volume were absorbed without rework. Each function now draws from the same repository, which is what made consistent, reliable reporting possible across the organization.