
Migrating the Supply Chain Analytics Platform That Moved a Fortune 500 Semiconductor Manufacturer off SAP HANA and into AI-Ready Infrastructure
A Fortune 500 semiconductor manufacturer was running supply chain analytics directly against live SAP HANA transactional data, degrading ERP performance and blocking AI adoption across yield forecasting, demand planning, and logistics. Ideas2IT built a parallel Snowflake-based analytics layer, migrated the CIBR data models, and deployed custom ML models for production yield prediction, purchase order delay detection, and die-level cherry-picking producing a 20% supply chain efficiency gain and 10–20% operational cost savings.

Client
A Fortune 500 semiconductor manufacturer

Industry
Manufacturing

Service
Data Modernization

Engagement
Active · Ongoing

Platform
SAP HANA → Snowflake + Azure ML
01 Challenge
SAP HANA is a transactional system. Running analytical queries against it at the frequency and depth supply chain planning requires creates performance contention on the ERP itself, the exact system the manufacturing operation depends on to function.
02 Solution
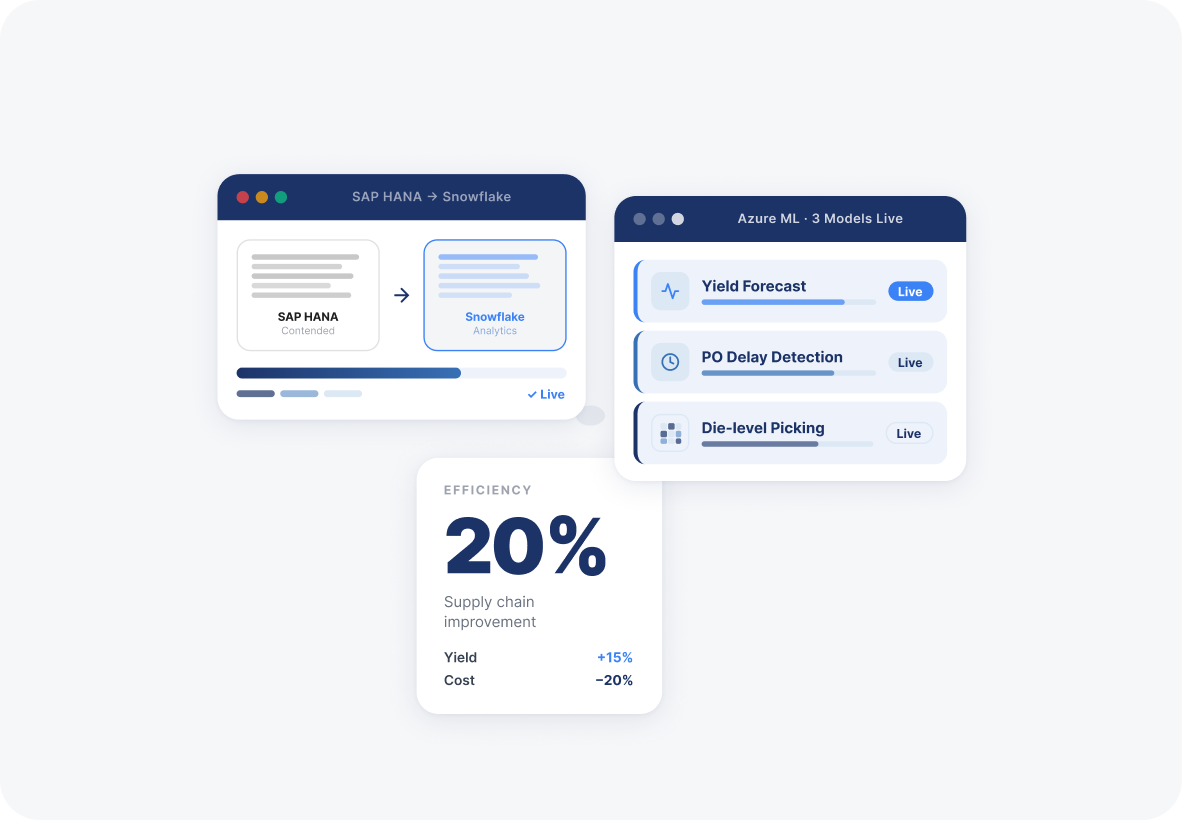
Ideas2IT built a parallel analytics architecture on Snowflake, separating analytical workloads from the live ERP without disrupting transactional performance. With the data layer in place, custom Azure ML models were deployed for production yield forecasting, purchase order delay prediction, and die-level cherry-picking optimisation.
03 Outcome
The analytics migration produced measurable improvement across every supply chain metric the client tracked: production yield, supply chain efficiency, time to delivery, operational cost, and sales throughput.
Phase 01
The data layer migration: moving supply chain analytics off SAP HANA without touching live ERP performance
The first architectural decision was the hardest constraint: any analytics migration had to run in parallel with the live SAP HANA ERP, not as a replacement of it.
The transactional system had to keep running without interruption while the analytical layer was being built alongside it. That required a deep working knowledge of the CIBR data models inside SAP HANA, most of which had no current documentation and whose subject matter experts were no longer available.
The team worked backwards, analysing the data available in the development environment, generating synthetic datasets to enable testing without production data access, and using Python libraries to navigate the complex access permission structure that had been blocking migration progress. The result was a Snowflake environment with replicated CIBR views, a Python Flask API microservice layer for ingestion, and a data foundation that made ERP analytical queries a Snowflake problem rather than a SAP HANA problem.
This Phase Produced
- SAP HANA → Snowflake migration pipeline (Schema and data model replication)
- CIBR data model replication in Snowflake (Backward-engineered from undocumented source)
- Synthetic data generation for dev/test (Enabled testing without production data access)
- Python Flask API microservice ingestion layer (Source-to-Snowflake data movement)
- Snowflake Connector integration (Live query and ingestion connectivity)
- Access permissions resolution framework (Python-based mitigation for complex permission structures)
Phase 02
AI models in production: yield forecasting, PO delay prediction, and cherry-picking optimisation on a ready data foundation
Once the data layer was stable, the question was which AI use cases were now tractable that had been impossible before.
Three stood out as highest operational value:
- predicting production yield and lead times so procurement could plan ahead of supply compression; identifying purchase order delays before they propagated downstream into manufacturing schedules; and optimising die-level cherry-picking, the process of selecting the highest-performing dies from a production wafer to maximise output quality.
- Each model was built on SKLearn and deployed through Azure ML into an AKS Kubernetes environment, with a React and D3.js dashboard giving supply chain planners direct access to model outputs without requiring data science intermediaries.
- The insight-driven dashboard combined live Snowflake queries with ML model inference, making predictive supply chain analytics accessible at the operations level rather than inside a data science team's tooling.
This Phase Produced
- Production Yield and Lead Time Forecast model (SKLearn model trained on historical supply chain data)
- Die-Level Cherry-Picking (DLCP) ML model (Wafer output quality optimisation)
- Purchase Order Delay prediction model (At-risk PO detection before downstream impact)
- Insight-driven supply chain dashboard (React + D3.js, live Snowflake queries + ML inference)
- Azure ML model deployment pipeline (Model training, deployment, and monitoring)
- MLOps pipeline on Azure AKS (Containerised model serving and retraining)
The Outcome
What changed in the supply chain once the analytics architecture was live
The performance gains across production yield, delivery time, and operational cost were the consequence of a single architectural decision held throughout: analytical and transactional workloads cannot share the same system at scale without degrading both. Building the Snowflake layer first, before any AI model was written, meant the ML models had a stable, current, and trustworthy data foundation to run against. The supply chain intelligence followed directly from the infrastructure discipline.