A mid-size auto components manufacturer ran a 90-day predictive maintenance pilot. The engineering team fed the model 18 months of sensor data from SCADA, three years of work order history from MES, and maintenance cost records from ERP. The model produced recommendations. The plant's maintenance team overrode 60 percent of them. But the project was cancelled after two quarters and the post-mortem attributed the failure to data quality.
The actual problem was that SCADA recorded machine ID PMP-07 stopping at 14:32 on a Tuesday. MES recorded work order WO-4471 pausing at 14:35 on the same day and ERP flagged a cost variance against equipment ID EQ-2047-B that afternoon. Nobody told the model that these three records described the same 47-minute production gap. The problem was operating on inputs that had no shared frame of reference.
According to Gartner, 60 percent of AI projects will be abandoned by organizations where AI-ready data infrastructure is absent. Research published by the MIT NANDA Initiative in July 2025 found that 95 percent of generative AI pilots delivered zero measurable P&L impact across the organizations studied.
Neither finding is a verdict on AI capability. Both describe precisely what happens when organizations deploy predictive models on top of data that was never built to mean the same thing across source systems.
The manufacturing data platform problem starts at the layer that most integration projects never finish building. The sections below explain that layer, how to build it, and where the work actually breaks down in practice.
Most vendor definitions describe a manufacturing data platform as a unified technological layer that ingests, standardizes, and serves data from shop-floor and enterprise systems. While this explanation is accurate, it is not useful for someone who has to build or evaluate one.
A more operationally useful definition is: a manufacturing data platform converts data produced by source systems into a canonical representation that any downstream consumer can query without needing to understand the source system's schema, timing logic, or domain vocabulary.
A data scientist building a yield prediction model should be able to query production event data without knowing whether it originated in SCADA, MES, or both. An AI model should not need to resolve conflicting identifiers for the same physical machine across three systems before inference can run.
Two distinctions that frequently get blurred in vendor conversations are worth stating directly.
A data historian is a component of a manufacturing data platform. A historian stores tag-based time-series data from SCADA and PLCs. It does not contextualize that data against work orders, production events, or quality outcomes. Treating it as the platform is one of the most common reasons AI initiatives stall.
MES is the execution layer where a manufacturing data platform is the analytical and contextual layer that sits above it. MES is one of the primary source systems the platform ingests and needs to make coherent alongside SCADA and ERP.
The integration problem is an architectural inheritance. ERP, MES, SCADA, and IoT were each designed by different engineering cultures, for different operational time horizons, under different security assumptions. The incompatibilities are structural.
While ERP runs in business time, the transactions are measured in hours, days, and reporting periods. The primary concern is financial accuracy here. As SCADA runs in machine time, measured in milliseconds and seconds, the primary concern here is real-time process control. MES runs in production time, measured in shifts and work orders. IoT devices run in event time, producing continuous streams that may or may not align to production cycles depending on how they were provisioned.
These reflect different definitions of what constitutes a meaningful unit of information. When a machine downtime event spans a shift change or a daylight saving transition, the event record becomes incoherent across systems unless a shared time reference has been deliberately engineered. Most organizations discover this at the model layer, long after the architecture decisions have been locked in.
Most manufacturers who have attempted integration at all have done it point-to-point: a custom connector between SCADA and MES here, an API bridge between MES and ERP there, a direct export from the historian to a reporting tool somewhere else. Each connection creates a bespoke dependency. When one system updates its schema, multiple connections break. When a new IoT device is added to the plant floor, a new bespoke integration is required. The architecture does not scale.
The ISA-95 standard defines the five-level hierarchy governing data flow between enterprise and plant-floor systems. Most manufacturing organizations have ISA-95 in their engineering documentation, but most of their actual architectures do not reflect it. The gap between the documented model and the implemented architecture is where point-to-point integrations accumulate and where every AI initiative eventually hits a ceiling.
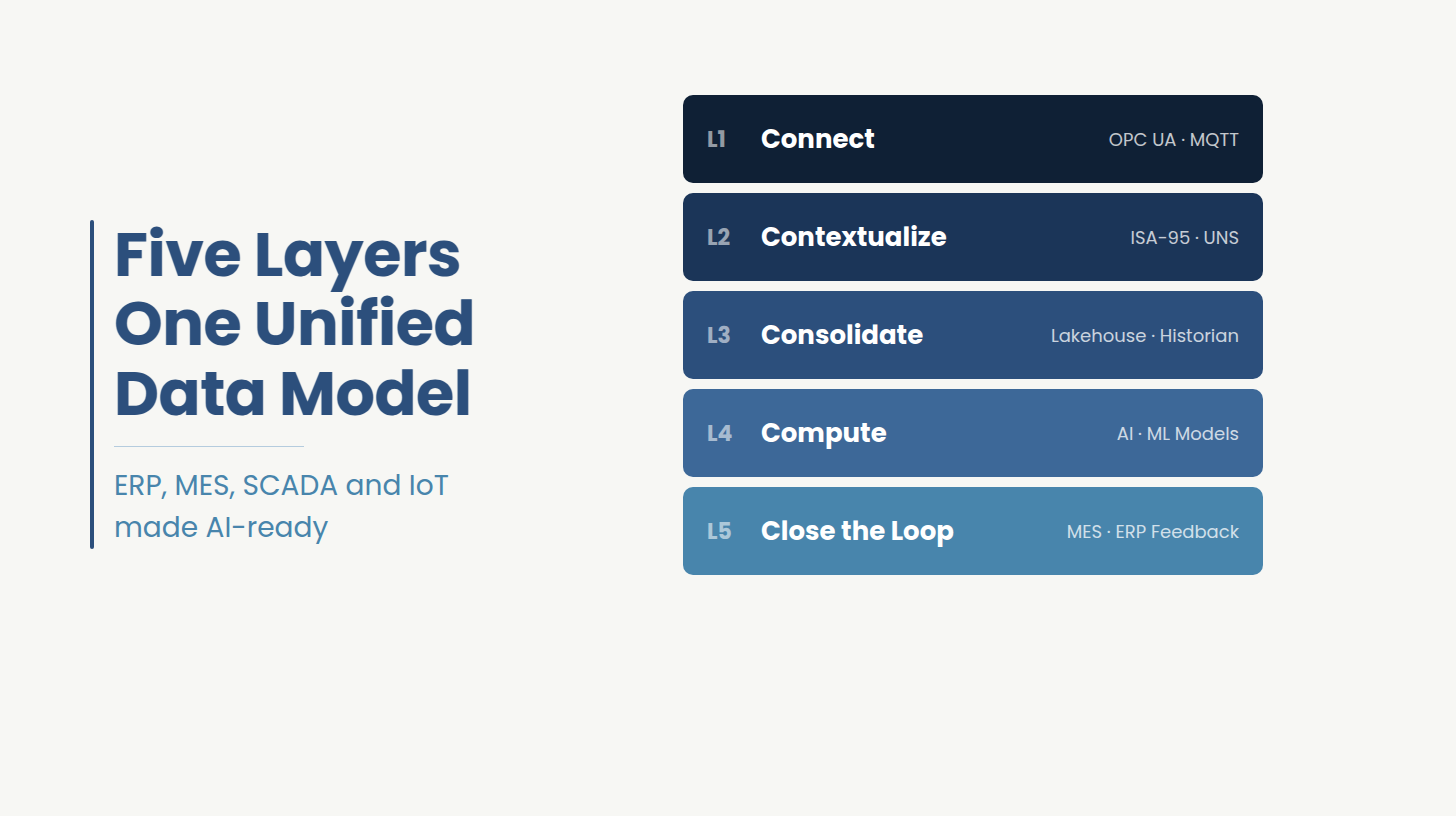
Building a manufacturing data platform capable of supporting AI use cases is a five-layer engineering problem. Each layer is necessary while none is sufficient on its own. The error most organizations make is solving the bottom layers and then treating the higher layers as configuration work.
Layer 1 is the OT protocol standardization. OPC UA handles device-level structured data exchange where schema consistency and reliability matter. MQTT with the Sparkplug B payload specification handles high-frequency, lightweight sensor streams where latency is the primary concern. Modbus and Profibus adapters bridge legacy PLCs that predate modern protocols.
*Most manufacturing data platform architectures use both. They are not alternatives.
Canonical data modeling using the ISA-95 hierarchy. Unified Namespace implementation. Every asset, event, and transaction is assigned a semantic identity that is consistent across all source systems. This is the layer that separates a functioning manufacturing data platform from a data swamp, and it is the layer most vendor platforms describe without actually implementing.
Implementing it requires engineering judgment about the specific asset hierarchy, the production event taxonomy, the quality schema, and how conflicts between systems with overlapping scope get resolved. There is no configuration wizard for this. It is an engineering design problem that requires engineers who understand what a downtime event means to a plant maintenance supervisor and how to model it in a structure a machine learning engineer can query without disambiguation.
AI-ready manufacturing data infrastructure, in operational terms, means Layer 2 is built. A data scientist querying production event data gets consistent asset identifiers, consistent timestamps, and a consistent definition of what constitutes a downtime event regardless of which source system recorded it first.
A Unified Namespace (UNS) is a single, shared data layer in which every asset, event, and measurement in a manufacturing environment is assigned one consistent semantic address, structured according to the ISA-95 five-level hierarchy: Enterprise, Site, Area, Line, and Work Cell. All source systems publish to and subscribe from this shared namespace rather than connecting to each other directly. That single architectural decision eliminates the point-to-point integration web where a schema change in one system breaks five downstream connections. Without it, the canonical data model has no authoritative home every consumer queries a different version of the same asset from a different source, and the identifier conflicts that surface in the opening story of this article persist indefinitely.
The OT Security Architecture Is a Data Access Problem
In most manufacturing environments, the OT network is segmented or air-gapped specifically to prevent the broad, continuous data access that analytics and AI require. This is not a final-phase compliance review. It is an architectural constraint that must be designed into the canonical data model from Layer 2: which data crosses which network boundary, at what frequency, through which validated channel, and with what audit trail.
Projects that treat OT security as a final-phase check consistently encounter six to twelve month delays after the architecture has already been committed. Design the data boundary at Layer 2 or redesign the entire Layer 2 later.
This layer is where the storage architecture happens. High-frequency sensor streams require a purpose-built time-series store. A lakehouse layer provides governed, queryable enterprise data at the analytical layer.
The historian coexistence strategy matters here. Most manufacturers cannot replace their existing historian in a single project. The architecture must accommodate the historian as a parallel source while the canonical layer is built above it. Organizations with 15 or more years of historian data should not frame it as something to migrate away from.
That historian is the ground-truth training data for every predictive maintenance and quality model the organization will build over the next decade. Replacing it before the canonical model is in place destroys the primary training corpus for the AI use cases that justified the platform investment. Preserve access to the historian while adding the canonical context layer above it.
One question that rarely gets answered directly in integration projects: how much historical data does AI actually need? Predictive maintenance models typically require 18 to 36 months of labeled event data to produce reliable failure-mode predictions. Organizations with less than 12 months of accessible historian data should factor a data collection runway into the AI use case roadmap before commissioning models, otherwise the first model is trained on data that does not yet represent the full range of failure conditions the plant will encounter.
The fourth layer is the AI and analytics layer. Predictive maintenance models, quality yield models, and throughput optimization all depend on the canonical data model built in Layer 2. Organizations that run AI directly on top of Layer 1 connectivity, bypassing Layer 2, produce exactly the kind of recommendations that operations teams override at high rates.
This is also where manufacturing quality analytics on a unified data layer starts to deliver verifiable results, because the model is finally working from a single coherent representation of production events rather than from three incompatible ones.
Final layer is the operational feedback piece. The platform's value is not in dashboards. It is in feeding model outputs back into execution systems: work orders generated from predictive maintenance alerts in MES, scheduling adjustments triggered by throughput anomaly detection, quality holds raised from sensor drift before a batch fails inspection. This is where AI investment produces measurable operational impact. Without Layer 5, the platform is a reporting tool. With it, it is an operational system.
According to Informatica's CDO Insights Survey published in 2025, 43 percent of chief data officers identified data quality and readiness as their primary obstacle to AI adoption. The five-layer model makes the failure mechanism visible.
Most organizations that commissioned AI pilots had Layer 1 partially built: some OPC UA connectivity, some historian data, perhaps an MES API integration. They then moved directly to Layer 4. Layer 2 was either skipped entirely or left for a future phase. Without a canonical data model, the AI runs on data that means different things depending on which system produced it.
What AI-ready data means in operational terms is that all three patterns have been resolved. Every asset has a consistent identifier across all source systems. Production events are timestamped in a shared time reference. Data governance rules define which system of record owns each data type. The MIT NANDA data is not a verdict on AI. It describes what happens when organizations deploy predictive models without first resolving these three problems at the layer below the model.
Build versus buy is the wrong frame. The right question is which components of the five-layer stack are commodity and which require custom engineering judgment. The answer is not the same across all five layers.
On cost and timeline: An analysis in 2026 estimated that custom manufacturing data integration projects range from $100,000 to $500,000 depending on source system count and data volume. Commercial platform licensing with configuration and integration services adds 150 to 200 percent of the stated license fee over a five-year horizon, a figure that almost never appears in vendor proposals. Cross-system data platform projects covering MES, SCADA, and IoT integration alongside ERP extend that timeline further. Organizations that compress the canonical modeling phase to hit a delivery date consistently return to rebuild it within 18 months.
Every integration vendor will say their platform unifies manufacturing data. These questions separate engineering firms that have built these architectures from resellers that have configured off-the-shelf tooling.
Not Sure Which Layers Need Custom Engineering?
If you have reached the build-vs-buy decision and are uncertain where the commodity boundary sits in your specific environment, the canonical data modeling scope is the piece that varies most between plants and is the hardest to estimate without looking at the actual system landscape.
Ideas2IT's engineering team runs a working session against your current stack. The session produces:
Most of the manufacturing data platform projects that stall at the canonical modeling phase share a procurement pattern: the engineering partner was selected for data architecture credentials, evaluated against a requirements document produced in a two-week discovery sprint, and deployed remotely against a system landscape they understood on paper but not in operation.
The problems that cause Layer 2 to fail are specific to how each plant's systems were configured, what shortcuts were taken during the original MES implementation, which PLCs were never properly documented, and how the controls team has been resolving timestamp conflicts manually for the past decade. None of that surfaces in a requirements document. It surfaces in plant operations standups, in conversations with the controls engineer who built the original SCADA schema, and in the edge cases that only appear when production runs at full capacity across a shift change.
What this means for partner selection:
The engineers who design the canonical data model need to be present in the plant environment through the Layer 2 design phase, not working from a remote requirements handoff. The distinction matters because the ISA-95 hierarchy decisions made in Layer 2 are architectural commitments. Reversing them after go-live is the 18-month rebuild pattern that accounts for most of the failed integration projects described in this article. The partner's architects should be embedded in the client's IT and OT environments simultaneously, attending plant operations standups alongside reviewing the MES schema with the controls team. Architectural decisions made with full operational context produce a different quality of canonical model than decisions made against documentation.
The second criterion is continuity. The engineer who designs the ISA-95 asset hierarchy should be the same engineer who resolves the conflict when SCADA reports a different downtime duration than MES for the same event. Handoff-heavy engagement models, where a senior architect designs the canonical layer and then hands implementation to a junior team, consistently produce gaps in the conflict resolution logic at exactly the points where production data is most ambiguous. Evaluate the partner's delivery model explicitly: ask whether the architects who design Layer 2 are present through go-live, or whether the engagement transitions to an implementation team at a defined milestone.
The third criterion is whether the partner owns the deliverable. A manufacturing data platform built on a proprietary vendor stack creates a dependency that persists long after the engagement ends. Every schema change, every new data source, every AI model update flows through the platform vendor's roadmap. Partners that deliver custom-engineered canonical layers on commodity infrastructure give the organization full ownership of the architecture and full control over its evolution.
For organizations in regulated manufacturing environments where data governance requirements extend into the OT boundary, a fourth criterion applies: whether the partner's information security management practices are certified to a standard compatible with the plant's regulatory obligations. This is the same requirement that surfaces in data governance requirements in regulated manufacturing environments, where every data movement across the OT boundary must be auditable before the first canonical model query runs.
Manufacturing data platform engagements begin with a scoped assessment of the current integration architecture. The assessment produces a layer-by-layer gap analysis, a platform selection recommendation for the commodity layers, and a custom engineering scope for the canonical modeling and UNS implementation work. For context on how Ideas2IT approaches manufacturing software development engagements, the service page covers the delivery model and typical engagement structure.
Most manufacturing organizations at this stage are missing a single coherent representation of data that already exists across four systems. The AI use cases are often already scoped. The models are ready to run. The canonical layer is the gap between the project plan and a production deployment.
What the assessment produces:
[1] Gartner. "By 2027, 60% of AI projects will be abandoned due to inadequate data foundations." Cited across multiple verified sources including MES Computing (April 2026) and mybusinessfuture.com (May 2026). Direct Gartner research note: "AI Projects in I&O Stall Ahead of Meaningful ROI Returns," April 7, 2026. Public citation: https://www.mescomputing.com/news/2026/ai/the-data-problems-undermining-midmarket-ai-projects-in-2026
[2] MIT NANDA Initiative. "The GenAI Divide: State of AI in Business 2025." MIT Media Lab Project NANDA, July 2025. Authors: Aditya Challapally, Chris Pease, Ramesh Raskar, Pradyumna Chari. Reported by Fortune, August 18, 2025. Fortune coverage: https://fortune.com/2025/08/18/mit-report-95-percent-generative-ai-pilots-at-companies-failing-cfo/ Full report: https://mlq.ai/media/quarterly_decks/v0.1_State_of_AI_in_Business_2025_Report.pdf
[3] Informatica. "CDO Insights 2025: Racing Ahead on GenAI and Data Investments While Navigating Potential Speed Bumps." Informatica / Wakefield Research, January 28, 2025. Survey of 600 global data leaders. Press release: https://www.informatica.com/about-us/news/news-releases/2025/01/20250128-global-data-leaders-seek-to-harness-the-power-of-genai-for-ai-driven-success.html Report landing page: https://www.informatica.com/lp/cdo-insights-2025_5039.html
Didn't find what you were looking for?