Switching software development vendors mid-project is more common than most engineering leaders realize. Projects stall, delivery slips, technical debt accumulates, compliance deadlines get closer, and confidence in the current partner starts to erode.
Most guidance on vendor transitions starts after the decision has already been made. The new vendor is selected, contracts are signed, and the handoff is underway. In reality, most CTOs and engineering leaders are still trying to answer a more fundamental question: should we switch at all, and if we do, what happens next?
The answer depends less on the vendor and more on the sequence. Teams get into trouble when they notify the outgoing vendor before securing critical assets, accept rescue or rebuild recommendations from teams that have never reviewed the codebase, overlook compliance obligations during the handoff, or carry the same governance issues into a new engagement.
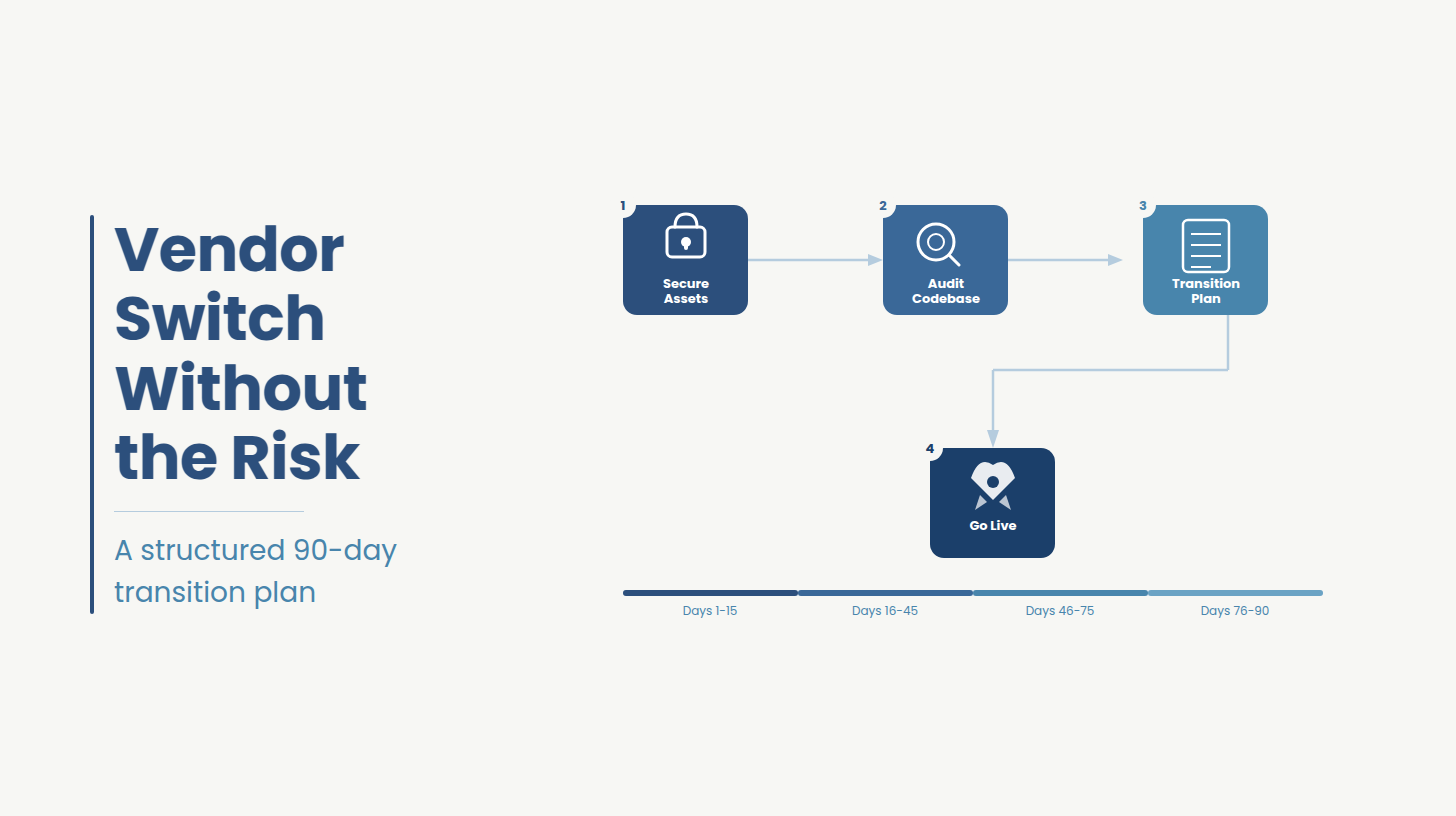
A successful transition follows a predictable path. First, secure ownership of your code, infrastructure, credentials, and documentation. Then establish the true state of the codebase through an independent assessment. Only then should you evaluate costs, timelines, transition risks, and potential delivery partners.
This guide walks through that process step by step: how to assess whether a switch is justified, how to evaluate rescue versus rebuild options, what a transition typically costs, how to maintain compliance and delivery continuity, and how to execute a structured 90-day handoff without creating new risks.
Before getting into the transition process itself, there are two situations where switching vendors is usually the wrong move, regardless of how dissatisfied you are with the current engagement.
Before planning a transition, make sure you're not creating a bigger problem than the one you're trying to solve. In most cases, there are only two situations where delaying a vendor switch is the better decision.
If a major launch, customer commitment, regulatory deadline, or board-visible milestone is imminent, introducing a new delivery team creates an additional source of risk at the worst possible time.
Ship the release first. Then assess the vendor transition. A project that is already struggling can usually absorb a transition six weeks later. A missed launch is much harder to recover from.
Every successful vendor switch has a single accountable owner. This person approves decisions, resolves conflicts, manages escalations, and maintains accountability across both vendors.
Without a designated owner, responsibility becomes fragmented, decisions slow down, and the transition inherits the same governance problems that often contributed to the original delivery issues.
If this role is not assigned, do that before engaging a replacement vendor. If neither condition applies, you are likely ready to evaluate a transition. The next step is understanding why vendor switches fail and how to avoid repeating the same problems with a new partner.
Most vendor transition guides start after the decision has been made. The new vendor is selected, contracts are signed, and the handoff is already underway.
In reality, most engineering leaders are still trying to answer a different set of questions. Should we switch at all? What happens to the codebase? How much will this cost? How long will delivery slow down? And how do we avoid turning one failing engagement into another?
The challenge is that your project does not pause while those questions are being answered. Deadlines remain. Customers are waiting. Compliance commitments still need to be met. Every week spent in uncertainty adds cost, risk, and delivery pressure.
The good news is that most vendor transitions are far more predictable than they appear. The projects that succeed tend to follow the same sequence. They secure critical assets before notifying the current vendor, establish the true condition of the codebase before discussing scope, and build a transition plan before handing over delivery responsibility. The projects that fail usually reverse that order.
This guide walks through the decisions, costs, risks, and execution steps involved in switching software vendors mid-project, from the first internal discussions to a complete handoff and recovery plan. The sections that follow walk through that sequence, starting with the first thing most companies get wrong: securing their assets before the vendor relationship changes.
One of the most common mistakes during a vendor transition is notifying the vendor first and collecting assets later.
Once a termination conversation happens, every access request, documentation request, or repository transfer takes place inside a relationship that has just been formally damaged. Even when both parties remain professional, priorities change.
Do it in reverse. Before discussing a transition with the vendor, make sure you control the assets listed below.
This exercise typically takes a day or less. Teams that already control their repositories, infrastructure, credentials, and documentation can move forward with options. Teams that do not often find themselves negotiating for access when they should be planning the transition.
Review your development agreement and confirm that intellectual property ownership transfers to your organization as work is created, not only at project completion.
If ownership language is unclear, involve legal counsel before the transition begins. Resolving IP questions during a vendor exit is significantly harder than resolving them beforehand. Also confirm in writing that the outgoing vendor retains no claim to source code, documentation, infrastructure configurations, or other project assets.
Third-party integrations are one of the most common sources of post-transition surprises.
Document every external dependency, including APIs, webhooks, authentication providers, payment gateways, analytics platforms, cloud services, and partner integrations. Then verify that credentials, API keys, and webhook configurations are owned through client-controlled accounts rather than vendor-managed accounts.
Many transition issues come from integrations nobody realized existed until they stopped working. Once your assets are secured, the next question is not which vendor to hire. It is understanding what you actually own.
A delayed project does not automatically mean a failed codebase. The answer determines your likely cost, timeline, and recovery options. That assessment comes from an audit, not a proposal.
The rescue vs rebuild decision is the most commercially significant call in the transition. It is also the most vulnerable to bias.
A vendor recommending a full rebuild is not making an abstract technical suggestion. It usually increases the size of the engagement by 2–3x. That is a real incentive in most delivery models. This is why the decision cannot be made inside vendor conversations.
Before any discussion on scope or pricing, you need an independent codebase audit that establishes what the system actually is today.
A proper audit does not “review code.” It quantifies system risk across a few specific dimensions that determine whether a handoff is safe. Most of this comes from static analysis tools, backed by engineering review.
The audit becomes useful when it moves from metrics to decision patterns
The most important threshold is structural change. If less than ~40% of the system needs fundamental change, refactoring almost always beats rebuilding on cost, speed, and risk.
If more than that, a hybrid model usually works best:
Full rebuilds sound cleaner. But they also reset all the business logic the system already got right.
A credible audit is an evidence pack. At minimum, it should include:
If a vendor cannot produce this before discussing scope, they are not ready to estimate the work. That is a signal in itself.
A focused audit typically takes:
The real constraint is not code size. It is system visibility. A well-structured 200,000-line codebase is faster to audit than a poorly documented 50,000-line one. Once you have this, the conversation changes. You are making a decision based on what the system actually is.
The next question becomes unavoidable: what does each path actually cost, and what are you really signing up for?
This is the section most guides skip. Without it, the transition never gets approved. You cannot justify a vendor switch with architecture concerns alone. You need a cost model that shows what happens if you do nothing and what changes if you move.
Before you calculate transition cost, you need a baseline: what it costs to continue as-is. In most failing engagements, cost does not show up as a single failure. It shows up as slow compounding loss across delivery, quality, and risk.
The key point is simple: you are already paying for the transition and you aren’t calling it that yet.
These are directional ranges. Actual numbers depend on system complexity, documentation quality, and compliance scope.
If the original project cost was $400,000:
The audit is not a sunk cost. It is what determines whether you are solving a $200K problem or a $600K one.
Most approvals fail because the cost is not framed correctly. You don’t present “transition cost.” You present a comparison of two futures.
Put this on one page:
Current monthly burn × realistic remaining timeline
Audit cost
Transition cost – continue cost
If this number is negative, the transition is financially justified.
Revenue loss or compliance impact tied to the next missed milestone.
This is the part most teams miss.
Boards don’t move on cost alone. They move when risk becomes explicit.
Software transitions are rarely approved because the model is perfect.
They are approved because someone clearly shows:
Once that is clear, the conversation stops being about vendors and becomes about control. And that leads to the next step: what a real rescue engagement actually looks like once the decision is made.
The following is an anonymized composite from mid-project rescue engagements. The structure reflects what is consistently seen in real transitions.
A healthcare software company was eight months into building a custom patient scheduling platform with an offshore development model.
The system was still “in progress,” but the risk profile had already shifted into delivery failure.
Estimated remediation scope: ~35% of the codebase
Here is a simple cost comparison.
The rescue path was selected. The Ideas2IT team:
Total time from engagement start to production-ready system: 16 weeks
This mirrors the kind of healthcare software development work we do most often patient scheduling, HIPAA-compliant workflows, and clinical systems where compliance debt can't be deferred indefinitely.
The CFO approved the transition within 48 hours. The decision was driven by a single-page summary:
The shift happened because the problem stopped being framed as a “vendor issue” and became a risk exposure decision with a defined financial impact.
Most rescues succeed because the decision becomes simple once:
With the decision approved and Ideas2IT engaged, the first priority was establishing a clean performance baseline. Without that, you cannot measure progress or control it.
Before the transition introduces noise into your system, capture a clear snapshot of where things stand today. This becomes the reference point for the next 90 days. It is also what your board will use to judge whether the new vendor is actually improving anything. If you don’t measure this upfront, every improvement later becomes a debate.
Here is a sample and clean baseline metric to establish.
These are stability signals. They show how predictable the system is before anything changes.
Don’t wait for the new team to define success, instead define it upfront. Set three checkpoints that the incoming vendor will be measured against from Day 1.
The goal in the first 30 days is stabilization. Improvement only becomes meaningful once the system is steady again.
Every metric needs a name next to it. Each KPI should have a clear owner on the incoming side who is responsible for:
If a metric has no owner, it will only be reported.
Most vendor transitions fail in measurement. The system changes with the team, but the definition of success is still vague. This step removes that ambiguity before work begins. With the baseline locked and ownership assigned, the transition can begin in a controlled way. The next step is where most teams lose structure: running the transition phase by phase, with clear exit criteria so no one is guessing what “done” looks like.
The transition follows a consistent structure regardless of project size. What changes is duration and the more context the incoming team has to reconstruct, the longer each phase takes.
In this phase, completeness matters more than depth.
The goal is simple: the incoming team should be able to build, test, and deploy and not understand every edge case.
Record everything. A 45-minute walkthrough, once captured, is more reliable than a document written later and never updated.
Most KT processes fail because they assume knowledge transfer is complete once information is shared. Whereas it is not.
Use a three-step loop per system:
Do not move a system into production ownership until teach-back passes. If the incoming team cannot explain it, the transfer is not complete regardless of number of sessions held.
If the outgoing vendor refuses participation, escalate via the transition assistance clause in the contract. If that clause does not exist, switch focus to structured reverse engineering from the codebase instead of waiting.
Two teams with simultaneous system access is one of the highest-risk states in a transition.
This phase is where that risk is actively reduced.
The goal is simple: reduce shared control before production responsibility shifts.
Define what types of changes are allowed while both teams are active. Ambiguity here is where most transition failures start.
Every deployment must have:
The parallel run is staged transfer.
Transfer ownership in order of risk:
Before revoking access, confirm:
Most transitions fail not because of engineering complexity, but because ownership is unclear at the wrong moments.
This structure removes that ambiguity by making ownership shift:
But even when execution is handled correctly, there is still one major gap most teams miss entirely. For healthcare, fintech, and enterprise systems, there is a second transition happening in parallel: compliance ownership. And that is where most hidden risk lives.
A vendor transition does not pause your compliance obligations. In fact, this is the exact window where most compliance gaps appear. And those gaps matter on their own, regardless of whether anything else fails.
Most compliance failures during transitions are not complex. They are sequencing problems.
SOC 2 audits do not evaluate intent instead evaluate traceability.
During a vendor transition, three control areas are most at risk:
Auditors do not expect transitions to be disruption-free. They expect them to be documented, controlled, and reviewable. If documentation is missing, the control failure is assumed even if the process was correct.
PCI-DSS v4.0 became mandatory in March 2024. During a vendor transition, Requirement 12.8 (third-party service providers) becomes critical.
Key requirements during handoff:
This is not a post-transition cleanup activity. It is a precondition for access.
Most teams treat compliance as a parallel track to delivery. During a vendor transition, it is not parallel. It is directly coupled to access, deployment, and ownership changes. If execution is Step 4, compliance is the constraint layer around it. Ignoring it accumulates risk silently. With compliance continuity handled alongside execution, the final question is selection. Which vendor can actually survive a rescue-grade transition without breaking structure, compliance, or continuity.
The biggest risk in a mid-project vendor switch is selecting a new vendor who repeats the same failure pattern in a slightly different form. Most failed transitions do not fail during delivery. They fail at selection when teams evaluate rescue work using greenfield criteria. Research on outsourcing remediation shows a consistent pattern: when governance and requirements issues are not fixed, switching vendors simply resets the cycle.
Some signals should end the evaluation immediately.
This step always happens while the outgoing vendor still has production access.
That constraint changes how evaluation must be run.
The highest-risk period in the entire transition is the overlap between:
That overlap must be time-boxed and controlled.
Vendor selection is the external decision. But success is determined internally:
A strong vendor cannot compensate for a weak transition system. Once this selection is complete, the transition becomes execution. And execution succeeds or fails based on how well the earlier steps were done and not on how good the new vendor looks on paper.
A vendor transition does not fail in execution first. It fails in alignment before Day 1. Most teams at this stage already have a technical plan. What they are missing is a clear internal case that turns the decision into something the business can approve and support.
Before your next board meeting, prepare a single page with four numbers:
This is the entire decision in financial form. Everything else is supporting detail. Boards do not approve transitions because the engineering case is strong. They approve them because the risk of not acting is clearly defined.
If you are the person who approved the original vendor, address it directly. Do not avoid it. Do not reframe it.
A clear version that works:
“We identified the failure pattern at month X. We acted on it. This is the transition plan and the revised delivery timeline.”
Boards do not penalize course correction. They penalize uncertainty.
What they need now is:
Clarity beats optimism at this stage.
Legal work must run in parallel, not after approval. They need to prepare two tracks:
Share the compliance section from Step 5 early. Do not let contract drafting happen without it.
Your engineers are not observers in this transition. They are participants. And in most organizations, this is where the most unspoken friction exists.
Before the new vendor arrives, make three things explicit:
Engineers who understand the structure upfront:
Engineers who discover the transition on Day 1 create delay because of uncertainty. This is where the transition becomes real inside the organization. If this step is done well, Day 1 is execution. If it is not, Day 1 becomes explanation. With stakeholders aligned, the transition becomes operational.
The final stage is stabilizing delivery after handoff begins, and ensuring the system does not degrade during the shift in ownership. The remaining question is which delivery partner is structurally capable of compressing the timeline that this guide has been describing throughout.
The 3–5 week cold-start delay in a standard vendor transition is not a product of project complexity. It is a product of starting from outside the client's environment. Ideas2IT's Forward Deployed Engineer model removes that variable structurally.
FDEs embed inside your existing environment from Day 1: your stack, your standups, your ticketing system, your OKRs. The audit begins on the first day of the engagement. Stabilization starts as findings come in, not after a separate ramp period ends.
Feature development resumes when stabilization is complete. The 10–14 day transition window described in Step 4 is a structural outcome of how FDEs enter an engagement, not a claim about pace.
For rescue engagements where the codebase carries significant documentation debt (true of almost every mid-project rescue), Ideas2IT deploys Explayn.ai during the audit phase.
Explayn.ai reads the existing codebase and generates plain-language explanations of what the code does: module-level descriptions, component relationships, data flow, and architectural decision records, derived directly from the code itself rather than from documentation that may not exist.
Code comprehension that would otherwise take a senior engineer three to four weeks of manual archaeology compresses to days. That output becomes the working reference the delivery team operates from and the artifact your internal engineers inherit when the engagement stabilizes.
Ideas2IT holds SOC 2 Type II certification and is an AWS GenAI Specialist Partner. For engagements with active HIPAA or SOC 2 requirements, the transition assessment maps the compliance posture gap between outgoing and incoming engagements, sequences the BAA and control handoff, and ensures no window opens between the termination of one agreement and the execution of the next.
The entry point is
A two-week transition assessment: codebase state, onboarding cost estimate, compliance posture gap, and a 90-day path to your next production milestone.
The output is a written finding you can take to your board, CFO, legal team, or any other vendor you are evaluating.
Start the Conversation
Every decision in this guide leads to that same starting point: know what you have before committing to any path forward.
A mid-project vendor switch is not inherently a high-risk decision. It becomes one when the sequence is wrong: when assets are collected after the notification, when the rescue vs rebuild call is made on the basis of an incoming vendor's proposal rather than an independent audit, when compliance obligations are managed as an afterthought, and when the internal business case is never built.
Every element of this guide addresses one of those failure modes. The sequence is designed so that each step produces a specific output the next step depends on: the audit outcome determines your cost range, the cost range builds the board case, the board case gets the transition approved, and the phased execution plan with exit criteria gives the incoming team and your stakeholders a shared definition of what success looks like at every stage.
The decision to switch vendors mid-project is almost always the right one, provided it is made before the compounding costs make the transition harder than the project itself.
The firms that execute these transitions successfully share one characteristic: they move from instinct to decision faster than the firms that stay too long.
If your project is in that position now, the right first move is an independent assessment of what you have.