John Snow Labs has just launched it’s version 3.1.0 of Spark NLP for Healthcare. It packs new interesting features and enhancements for improvising Natural Language Processing for Healthcare. Building systems that understand medical texts is now a lot simpler and faster with the new Spark NLP update. While the overall setup of the delivery pipelines and modeling remains fairly unchanged, the new release makes Spark NLP a better experience for Healthcare Data Scientists. But John Snow Labs has gotten fairly aggressive, with its various improvements in the existing features and multifold development in the overall service offerings. The new release sure has got the world of healthcare analytics excited.Here is a summary of all the new features of Spark NLP 3.1.0.
- Improved load time & memory consumption for SentenceResolver models
- New JSL Bert Models.
- JSL SBert Model Speed Benchmark.
- New ICD10CM resolver models.
- New Deidentification NER models.
- New column returned in DeidentificationModel
- New Reidentification feature
- New Deidentification Pretrained Pipelines
- Chunk filtering based on confidence
- Extended regex dictionary functionality in Deidentification
- Enhanced RelationExtractionDL Model to create and identify relations between entities across the entire document
- MedicalNerApproach can now accept a graph file directly.
- MedicalNerApproach can now accept a user-defined name for log file.
- More improvements in Scaladocs.
- Bug fixes in Deidentification module.
- New notebooks
What’s New in Spark NLP 3.1.0?
Annotators
The new Spark NLP 3.1.0 comes with over 2600+ new pre-trained models and pipelines in over 200+ languages. The new DistilBERT, RoBERTa, and XLM-RoBERTa annotators support HuggingFace (Auto-encoding) models in Spark NLP and extend support for new Databricks and EMR instances. Some new featured Transformers models are:[caption id="attachment_10429" align="aligncenter" width="687"]

Src: https://nlp.johnsnowlabs.com/docs/en/licensed_release_notes[/caption]The new annotators set the stage for state-of-the-art autoencoding models for Natural Language Processing (NLP).
- DistilBERT: Pre-trained language models are usually computationally expensive, so it is difficult to efficiently execute them on resource-restricted devices. Spark NLP now supports BERT models designed for knowledge distillation. The main idea behind knowledge distillation is to simplify these large (teacher) models into smaller yet almost as efficient and more production-friendly (student) models.
- RoBERTaEmbeddings annotator: RoBERTa (Robustly Optimized BERT-Pre Training Approach) models deliver state-of-the-art performance on NLP/NLU tasks and a sizable performance improvement on the GLUE benchmark. With a score of 88.5, RoBERTa reached the top position on the GLUE leaderboard
- XlmRoBERTaEmbeddings annotator: XLM-RoBERTa (Unsupervised Cross-lingual Representation Learning at Scale) is a large multi-lingual language model, trained on 2.5TB of filtered CommonCrawl data with 100 different languages. It also outperforms multilingual BERT (mBERT) on a variety of cross-lingual benchmarks, including +13.8% average accuracy on XNLI, +12.3% average F1 score on MLQA, and +2.1% average F1 score on NER. XLM-R performs particularly well on low-resource languages, improving 11.8% in XNLI accuracy for Swahili and 9.2% for Urdu over the previous XLM model.
Sentence Resolver Models with better load time improvement
All the Sentence Resolver models in Spark NLP now have faster load times. The new models are about 6X times faster compared to previous versions. Additionally, the load process takes up lesser memory and reduces the chances of Out of Memory (OOM) errors during runtime. This will have a direct effect on reducing your systems’ hardware requirements.
New John Snow Labs sBert models
The new release includes sBert models in TF2 and is fine-tuned on MedNLI, NLI and UMLS datasets with various parameters to cover common NLP tasks in the medical domain.[caption id="attachment_10430" align="alignnone" width="673"]

John Snow Labs sBert models[/caption]The new annotators set the stage for state-of-the-art autoencoding models for Natural Language Processing (NLP).
- DistilBERT: Pre-trained language models are usually computationally expensive, so it is difficult to efficiently execute them on resource-restricted devices. Spark NLP now supports BERT models designed for knowledge distillation. The main idea behind knowledge distillation is to simplify these large (teacher) models into smaller yet almost as efficient and more production-friendly (student) models.
- RoBERTaEmbeddings annotator: RoBERTa (Robustly Optimized BERT-Pre Training Approach) models deliver state-of-the-art performance on NLP/NLU tasks and a sizable performance improvement on the GLUE benchmark. With a score of 88.5, RoBERTa reached the top position on the GLUE leaderboard
- XlmRoBERTaEmbeddings annotator: XLM-RoBERTa (Unsupervised Cross-lingual Representation Learning at Scale) is a large multi-lingual language model, trained on 2.5TB of filtered CommonCrawl data with 100 different languages. It also outperforms multilingual BERT (mBERT) on a variety of cross-lingual benchmarks, including +13.8% average accuracy on XNLI, +12.3% average F1 score on MLQA, and +2.1% average F1 score on NER. XLM-R performs particularly well on low-resource languages, improving 11.8% in XNLI accuracy for Swahili and 9.2% for Urdu over the previous XLM model.
Sentence Resolver Models with better load time improvement
All the Sentence Resolver models in Spark NLP now have faster load times. The new models are about 6X times faster compared to previous versions. Additionally, the load process takes up lesser memory and reduces the chances of Out of Memory (OOM) errors during runtime. This will have a direct effect on reducing your systems’ hardware requirements.
New John Snow Labs sBert models
The new release includes sBert models in TF2 and is fine-tuned on MedNLI, NLI and UMLS datasets with various parameters to cover common NLP tasks in the medical domain.[caption id="attachment_10430" align="alignnone" width="673"]
John Snow Labs sBert models[/caption]The new annotators set the stage for state-of-the-art autoencoding models for Natural Language Processing (NLP).
- DistilBERT: Pre-trained language models are usually computationally expensive, so it is difficult to efficiently execute them on resource-restricted devices. Spark NLP now supports BERT models designed for knowledge distillation. The main idea behind knowledge distillation is to simplify these large (teacher) models into smaller yet almost as efficient and more production-friendly (student) models.
- RoBERTaEmbeddings annotator: RoBERTa (Robustly Optimized BERT-Pre Training Approach) models deliver state-of-the-art performance on NLP/NLU tasks and a sizable performance improvement on the GLUE benchmark. With a score of 88.5, RoBERTa reached the top position on the GLUE leaderboard
- XlmRoBERTaEmbeddings annotator: XLM-RoBERTa (Unsupervised Cross-lingual Representation Learning at Scale) is a large multi-lingual language model, trained on 2.5TB of filtered CommonCrawl data with 100 different languages. It also outperforms multilingual BERT (mBERT) on a variety of cross-lingual benchmarks, including +13.8% average accuracy on XNLI, +12.3% average F1 score on MLQA, and +2.1% average F1 score on NER. XLM-R performs particularly well on low-resource languages, improving 11.8% in XNLI accuracy for Swahili and 9.2% for Urdu over the previous XLM model.
Sentence Resolver Models with better load time improvement
All the Sentence Resolver models in Spark NLP now have faster load times. The new models are about 6X times faster compared to previous versions. Additionally, the load process takes up lesser memory and reduces the chances of Out of Memory (OOM) errors during runtime. This will have a direct effect on reducing your systems’ hardware requirements.
New John Snow Labs sBert models
The new release includes sBert models in TF2 and is fine-tuned on MedNLI, NLI and UMLS datasets with various parameters to cover common NLP tasks in the medical domain.[caption id="attachment_10430" align="alignnone" width="673"]
John Snow Labs sBert models[/caption]
Additional Improvements in the sBert Models
- Full utilization of accelerated hardware GPUs, through migration from MarianTransformer to BatchAnnotate
- Implementation of a new BPE tokenizer for RoBERTa and XLM models. This tokenizer will use the custom tokens from Tokenizer or RegexTokenizer and generates token pieces, encodes, and decodes the results
- Additional support for new Databricks runtimes to Spark NLP
- Additional support for EMR 6.3.0
Chunk Filtering based on Confidence
The new update has a brand new annotator for loading a CSV with both the required entities and confidence thresholds - this is the ChunkFiltererApproach. This annotator will produce a ChunkFilterer model and let users filter models with a specified level of confidence and for a specific treatment.
New Notebooks
Along with all the updates, John Snow Labs has also released a new notebook to help the medical systems reproduce their peer-reviewed NER paper. The notebook also contains several databricks case study notebooks that show examples of how to work with oncology notes dataset and OCR on databricks.
Application-based Feature Improvements
Apart from the technical improvements and model additions in the new release, Spark NLP also has a lot of the improvements in features that are user experience-oriented and would make several day-to-day challenges in Healthcare NLP easier for any use case. Most use cases in healthcare NLP deal with extracting information from unstructured medical data. This new release has made this a lot easier and sophisticated with its newly added features.
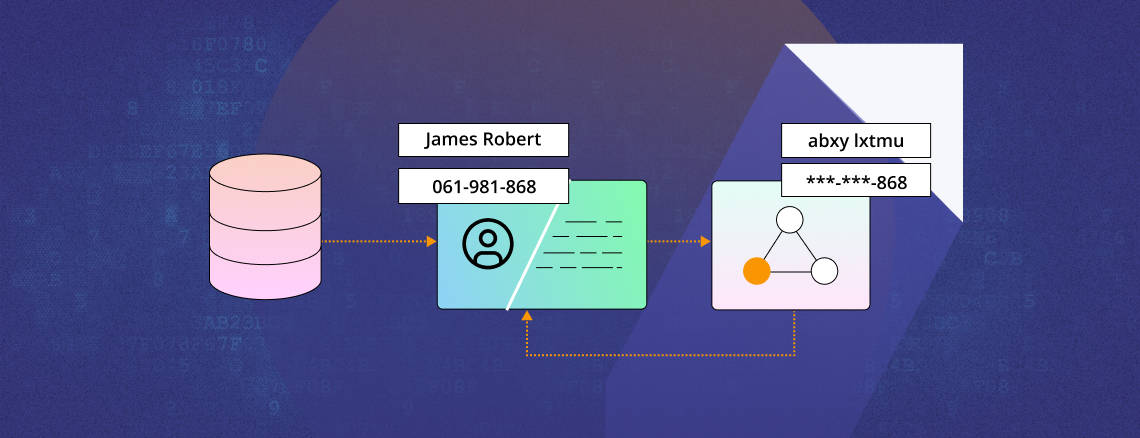
Masking and Re-identifying PHI
This is a major part of the application-based features in the recent release. Masking personal data is a vital requirement of Healthcare analytics. Full end-to-end masking of PHI is available at a more granular level and goes to identify and de-identify as many as 23 entities. This feature till now was limited to deidentification. But it now comes with re-identification of masked data at ease in the latest release. The improvement metrics from the previous versions are listed below.


Extracting ICD codes from synonyms
New sBERT models can offer more accurate ICD10 code extraction functionalities. These models are fine-tuned on MedNLI, NLI and UMLS, and a few other datasets. Previously, only entity-specific predictions of disease code were possible through NLP. Given the benchmarks released for these sBERT models, very specific ICD10 codes (for e.g., cancer, bladder cancer, liver cancer, etc.) can be now extracted, i.e., different categories and subcategories of a disease can be easily detected now. Healthcare data scientists can now extract ICD10 codes from fairly unstructured sentences, even when the entities cannot be directly detected from the synonyms.

Entity Relation Extraction from Multiple sentences
Previously only relationships between two or more entities in a sentence was possible. With the new release, related entities across different sentences all over the document can now be extracted. This optimizes any relationship features on the document level. This can be applied to all existing Healthcare models for optimal information extraction. A new option has been added to RENerChunksFilter to support pairing entities from different sentences using .setDocLevelRelations(True), to pass to the Relation Extraction Model.This sums up the latest features released by John Snow Labs in the latest update of Spark NLP. There are many other minor changes in this update. To read more about these updates read the official release notes of Spark NLP 3.1.0.Spark NLP was always reckoned among the best NLP solutions in the Healthcare Analytics industry. With the release of Spark NLP 3.1.0, it has only reinforced its ‘state-of-the-art’ proposition.







.png)


.png)


.webp)