



Healthcare systems around the world are complex and vary significantly. They are increasingly becoming data-driven. One of the challenges in healthcare analytics is the unstructured, often messy nature of the data, which hinders effective analysis. This valuable information is scattered throughout the system in forms such as lab test reports, medical claims, images, clinical notes, and critical time-series statistics like heart rates and ECG readings.
Current research in healthcare analytics focuses on extracting meaningful insights from these unstructured sources, including discharge summaries, clinical notes, and medical images
Every health care provider, payer, and life sciences company needs to solve the problem of structuring the data to make better patient support decisions through AI. This is also important also in B2B healthcare services like claims and insurances and other services. "These claims and insurance covers become very important" even during the analysis of patient data to improve patient care and growth in revenue from the care-giver side as well as the claims company’s side.
AWS HealthLake is a powerful service designed to help healthcare organizations store, transform, and analyze health data at scale. By leveraging machine learning and advanced data analytics, HealthLake enables users to create a comprehensive view of patient health information. Here’s a closer look at how AWS HealthLake works:
HealthLake allows healthcare organizations to ingest a variety of health data formats, including electronic health records (EHRs), medical imaging data, and other clinical documents. It supports standard formats like FHIR (Fast Healthcare Interoperability Resources), enabling seamless integration from different sources.
Once data is ingested, HealthLake automatically transforms it into a unified format. It normalizes and organizes the information, ensuring consistency across datasets. This process includes extracting key medical concepts and relationships using machine learning models, facilitating easier analysis.
HealthLake stores data in a secure, scalable environment. It utilizes Amazon S3 for storage, providing durable and cost-effective solutions for managing vast amounts of health data while ensuring compliance with industry regulations.
The service indexes health data, making it easily searchable. Users can run complex queries to retrieve specific information, enabling efficient data retrieval and analysis. This is crucial for generating insights and improving patient care.
With integrated analytics capabilities, HealthLake allows organizations to derive meaningful insights from their data. Users can apply machine learning models to identify trends, predict patient outcomes, and enhance decision-making processes.
HealthLake supports interoperability by allowing healthcare organizations to share data securely with partners, applications, and systems. This promotes collaboration and enhances the overall healthcare ecosystem.
Users can visualize health data through various tools and dashboards, facilitating easy understanding and reporting. This helps stakeholders make informed decisions based on real-time insights.
Amazon HealthLake offers numerous advantages for healthcare organizations looking to manage and analyze health data effectively. Here are some key benefits:
Is Amazon the new go-to for solving this problem? In December 2020, Amazon launched Amazon HealthLake as an AWS service, which will automatically understand and extract medical information including rules, procedures, and real-time diagnoses. Amazon HealthLake is a HIPAA-eligible service that enables healthcare providers, payers, and pharmaceutical companies to store, transform, query, and analyze health data at a petabyte-scale. It performs much of the work of organizing, indexing, and structuring patient information, to provide a complete view of each patient’s medical history in a more secure, compliant, and auditable manner. "Healthlake normalizes the data for ease in the use of further analysis". Upon ingestion, Amazon HealthLake uses machine learning models that are trained to understand medical terminology to identify and tag each piece of clinical information, index events into a timeline view, and enrich the data with standardized labels (e.g., medications, conditions, diagnoses, procedures, etc.), which facilitates quick and easy information search retrieval.
For example, if a healthcare provider wants to know “What is the immunization status for their patients?”. This could be easily queried from the timelined data by searching for “Immunization” with search parameters as “patients” for a detailed view of immunization status for different diseases for different patients.
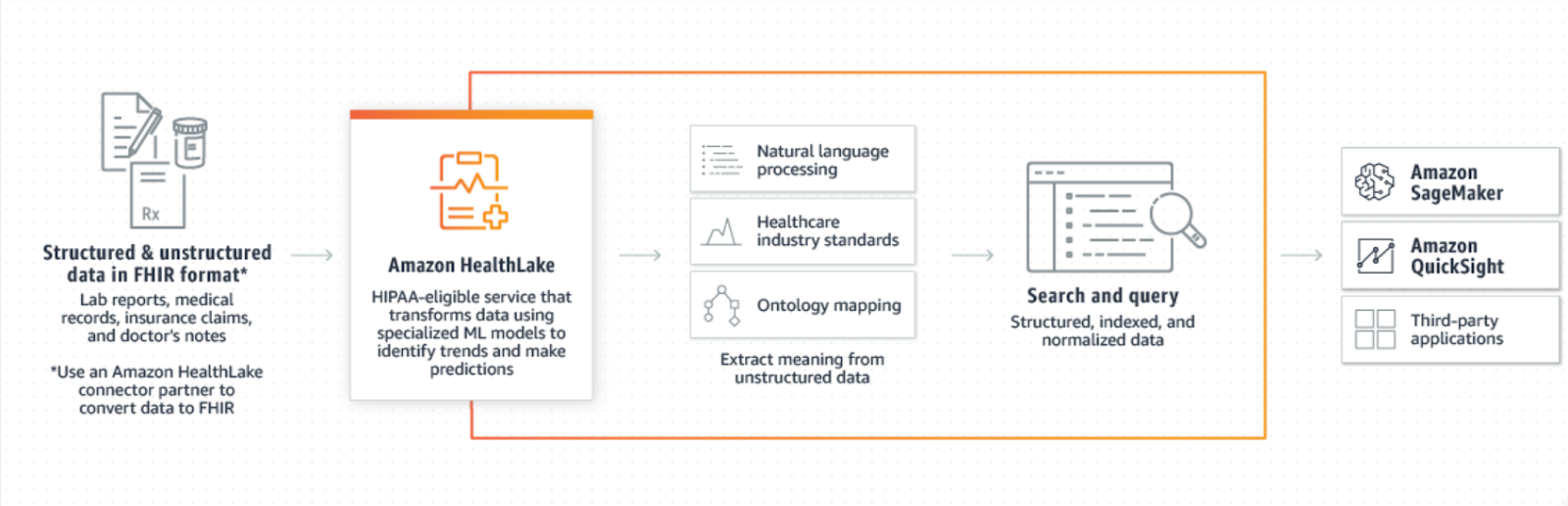
Image Courtesy: AWS
Healthlake recognizes interoperability standards, by including Fast Healthcare Interoperability Resources(FHIR R4), which is a standardized data sharing format in the healthcare systems. "This enables providers to collaborate more effectively" and allows unfettered access to their medical information. Support for other formats, like X12, CCD, etc. may be on the way. Health analytics will be much easier with all the heavy lifting being taken care of by this end-to-end service. In the next section, we will discuss some of the major capabilities of HealthLake.
Let’s look at some of the major capabilities of HealthLake in better detail to understand this service better.
Bulk import allows customers to easily migrate their on-premise FHIR files including clinical notes, lab reports, insurance claims, and more to an S3 bucket in their account, where their data can be used in further downstream applications.
Data Store helps you index all of your information so it can be easily queried. The Data Store creates a complete view of each patient’s medical history in chronological order and facilitates the exchange of information using the V4 FHIR specification. "The Data Store is always running to keep" your index up to date, offering you the ability to query the information anytime using the standard FHIR Operations with durable primary storage and index scaling. Amazon HealthLake meets rigorous security and access controls to ensure patients’ sensitive health data is protected and meets regulatory compliance.
Integrated medical natural language processing (NLP) transforms all of the raw medical text data from the Data Store using specialized ML models that have been trained to understand and extract meaningful information from unstructured healthcare data. "With integrated medical NLP, you can automatically extract" entities (e.g., medical procedures, medications), entity relationships (e.g., a medication and its dosage), entity traits (e.g., positive or negative test result, time of procedure), and Protected Health Information (PHI) data from your medical text. For example, HealthLake can accurately identify patient information from an insurance claim, extract laboratory reports, and map to medical billing codes like ICD-10 in minutes, rather than hours or weeks.
Amazon HealthLake supports FHIR CRUD (Create/Read/Update/Delete) and FHIR Search operations. You can query records by performing a Create Operation for adding new patients and their information, like medications. You can read the most recent version of that record by performing a Read Operation. "You can update a previously created" record by performing an Update Operation. As per the FHIR specification, deleted data is only hidden from analysis and search results; it is not deleted from the service, only versioned. You can also search with predefined filters to find all the information on a patient.
Amazon HealthLake enables customers to bulk export their FHIR data from the HealthLake Data Store to an S3 bucket. With Amazon QuickSight, developers can create dashboards on the exported and normalized data to quickly explore trends about their patients or population and predict events and personalize care at the individual level. Developers can also build, train and deploy their own ML models on their data with Amazon SageMaker.
A complete guide to creating the Data Store and importing data onto it can be found in their detailed documentation here.
At this point, when we have discussed the major services available in HealthLake, Let’s see some of the integral parts of those services, to see how the whole service comes together. In this light, it’s important to understand how the healthcare resources(here FHIR) are managed, or how NLP integration in the service makes it stand out. In the next two sections, we shall discuss this, and succeeding that would be a snippet of demonstration of the queries that you can do for information retrieval.
With HealthLake, healthcare providers can access a comprehensive view of a patient’s medical history, facilitating accurate telemedicine consultations. Aggregated data allows for a complete understanding of the patient’s health status remotely.
HealthLake enables the integration of genomic data with electronic health records (EHRs). This empowers providers to analyze genetic profiles and link them to specific health conditions, leading to personalized treatment plans and targeted therapies.
HealthLake assists organizations in analyzing population health trends and outcomes, helping identify appropriate interventions and improving care management options for specific patient populations.
By compiling a complete view of a patient’s medical history, HealthLake helps hospitals, insurers, and life sciences organizations close care gaps, enhance care quality, and reduce costs.
HealthLake provides essential analytics and machine learning tools that improve hospital operational efficiency and reduce waste.
Researchers can leverage HealthLake’s extensive healthcare data to identify patterns, discover insights, and conduct studies that advance clinical research and personalized medicine.
HealthLake supports the ingestion and processing of streaming data from medical devices and sensors, enabling healthcare organizations to identify critical events for proactive patient management.
HealthLake offers a secure and scalable data lake for healthcare data, simplifying advanced analytics and generating insightful reports to drive better decision-making.
In an active Data Store at HealthLake, users can create, delete, update resources by using the FHIR Rest custom-software-development. The following table lists the operation that can be performed for FHIR resource management.
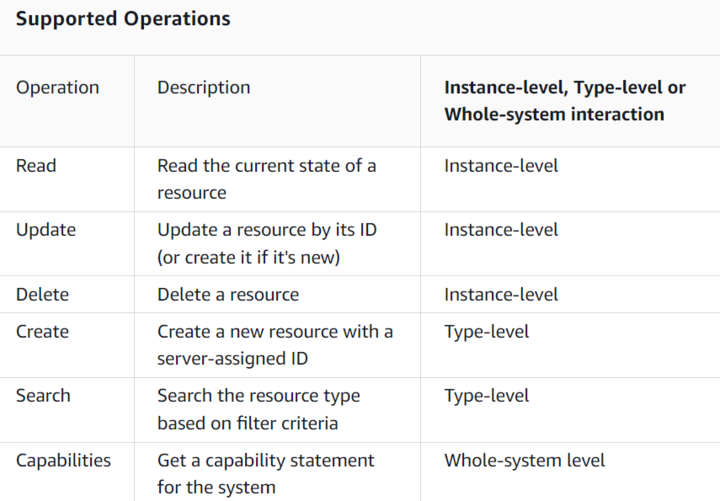
Image Courtesy: AWS
There are as many as 71 resource types that are supported by Healthlake, a comprehensive list of which can be found here.
Some common search parameters for querying FHIR data can be listed as below:

Image Courtesy: AWS
Amazon HealthLake automatically integrates with natural language processing (NLP) for the DocumentReference resource type. The integrated medical NLP output is provided as an extension to the existing DocumentReference resource. The integration involves reading the text data within the resource, and then calling the following integrated medical NLP operations: DetectEntities-V2, InferICD10-CM, and InferRxNorm. "The response of each of the integrated medical NLP custom-software-development" is appended to the DocumentReference resource as an extension that is searchable. This enables users to identify patients through elements of their records that were previously buried within the unstructured text. When you create a resource in HealthLake, the resource is updated with the response from the integrated medical NLP operations. "These extensions follow the FHIR format for extensions with" an identifying URL and the respective value for the URL.
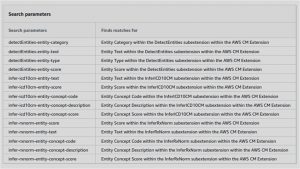
Image Courtesy: AWS
Users can query information regarding the patients, medications, disease codes from the data very easily in HealthLake. As discussed before, the NLP integration makes it possible to do very specific queries. Let’s look at the following two queries.
Say, we would like to know what the immunization status of the patients is. We need to make a query similar to the following.
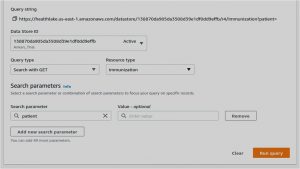
Image Courtesy: AWS
The value is optional. You can put the patient ID for referring to a specific patient. This will return a list of all patients with immunization history and their status. One small snippet is attached for better understanding.
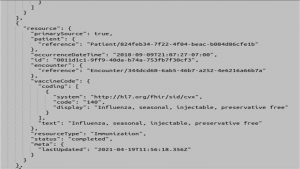
Image Courtesy: AWS
The above result shows that the influenza immunization has been “completed” for the patient. The patients reference ID which is seen above can be used for specific queries regarding
Let’s say, from the clinical notes and documents, you would like to know which patients intake a certain medicine, say “Clonidine” (a drug used in the treatment of hypertension). Let’s make the following query.
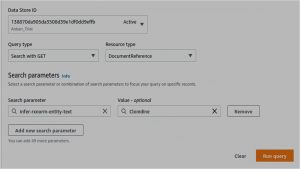
Image Courtesy: AWS
A snippet from the results are shown as follows.
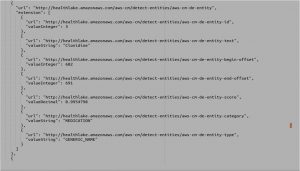
Image Courtesy: AWS
The specific medicine is identified, along with the matching score, category, and type. This type of information becomes necessary features for further study, say related to Hypertension and the likes of it.
At the final step, when the imported data is normalized and all transformations are ready, the end job is to export this standardized data for further analysis. The next section discusses that in brief.
The normalized data is exported to S3 for further analysis. You can simply do this with a few clicks in the AWS console. Below is a snippet of the export job, if you wish to go into further details please visit the export job documentation here.
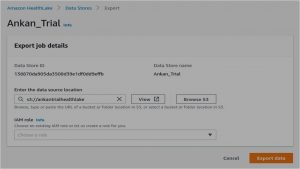
Image Courtesy: AWS
You need to provide the S3 location and select a suitable IAM role and you’re good to go!
The utility of AWS HealthLake ends at the export of the FHIR data. Analysis of the data and building machine learning models need to be done separately through Quicksight and Sagemaker.
HealthLake is in Preview as of the date of writing this blog and is free to use during this period. The following pricing will be effective at General Availability.
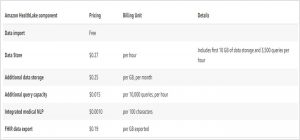
Image Courtesy: AWS
Healthlake is a fairly end-to-end AWS service. However, there are very few shortcomings that I think the user might face while using HealthLake. The following holds true at the time of writing this blog, or until subsequent releases address them.
Only FHIR(R4) format data is supported here. Healthcare systems that still haven’t migrated to FHIR, may face difficulty using this service. Resources need to be converted to FHIR for use in this service.
The export job, transforms and exports the whole data pool in S3. There is no provision to export the queried data to S3, which can be useful for specific studies. For example, if a study is based on only blood sugar patients, they need to be filtered out after export.
This is based on the experience while using the preloaded data for queries. Sometimes, results are inconsistent with what is queried. Several redundant information is sometimes likely to appear in such queries, making the readability of the results complex.
Resource search results appear in FHIR format and no other easy-to-read format like tables and data frames are not supported. Until someone is experienced with FHIR and interoperability, it might cause a user difficulty in full comprehension of the query results.
As the industry increasingly harnesses the potential of health data, Amazon HealthLake stands out as a transformative force, reshaping healthcare delivery and paving the way for the future of medicine.
Ideas2it is an official AWS (Amazon Web Services) Advanced Consulting Partner and Training partner helping people develop knowledge of the cloud and help their businesses aim for higher goals using best-in-industry cloud computing practices and expertise. We are on a mission to build a robust cloud computing ecosystem by disseminating knowledge on technological intricacies within the cloud space. Explore our cloud capabilities that can help organizations like yours reach new heights.
Reference Link: https://aws.amazon.com/healthlake/
What is AWS HealthLake?
AWS HealthLake is a managed service that allows healthcare organizations to securely store, process, and analyze health data at scale. It transforms both structured and unstructured health data into a standardized format (FHIR) for better interoperability and insights.
How does AWS HealthLake integrate with other AWS services?
AWS HealthLake works seamlessly with AWS tools like Amazon S3, Redshift, and SageMaker, enabling efficient data storage, analytics, and AI/ML processes while maintaining scalability and security.
How do I convert my current data to FHIR?
AWS HealthLake offers automated data transformation features to convert your healthcare data (like HL7) into the FHIR format.
What FHIR resources does AWS HealthLake support?
AWS HealthLake supports a comprehensive range of FHIR resources, including Patient, Encounter, Observation, Medication, Condition, and many others, ensuring data interoperability.
Is AWS Healthlake HIPAA-eligible?
Yes, AWS HealthLake is designed to be HIPAA-eligible and complies with necessary healthcare data protection standards under the Health Insurance Portability and Accountability Act.
What security and privacy measures does AWS HealthLake have in place?
AWS HealthLake uses encryption (both in transit and at rest), identity and access management (IAM) controls, and robust monitoring features to protect your data, ensuring security, privacy, and compliance with regulations.



%20Hybrid%20Cloud%20Strategies%20for%20Modernizing%20Legacy%20Applications.avif)
%20Application%20Containerization_%20How%20To%20Streamline%20Your%20Development.avif)


