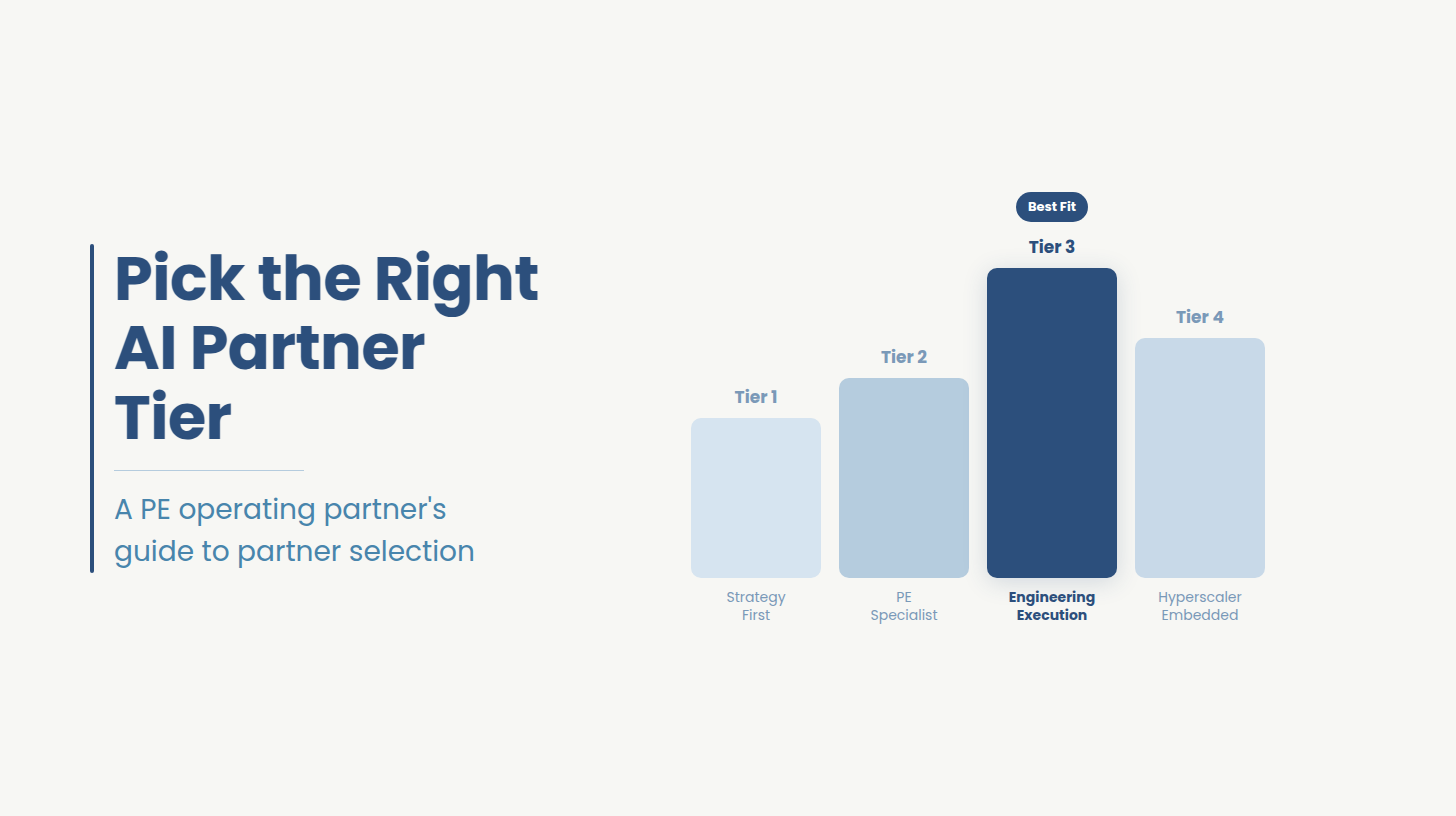
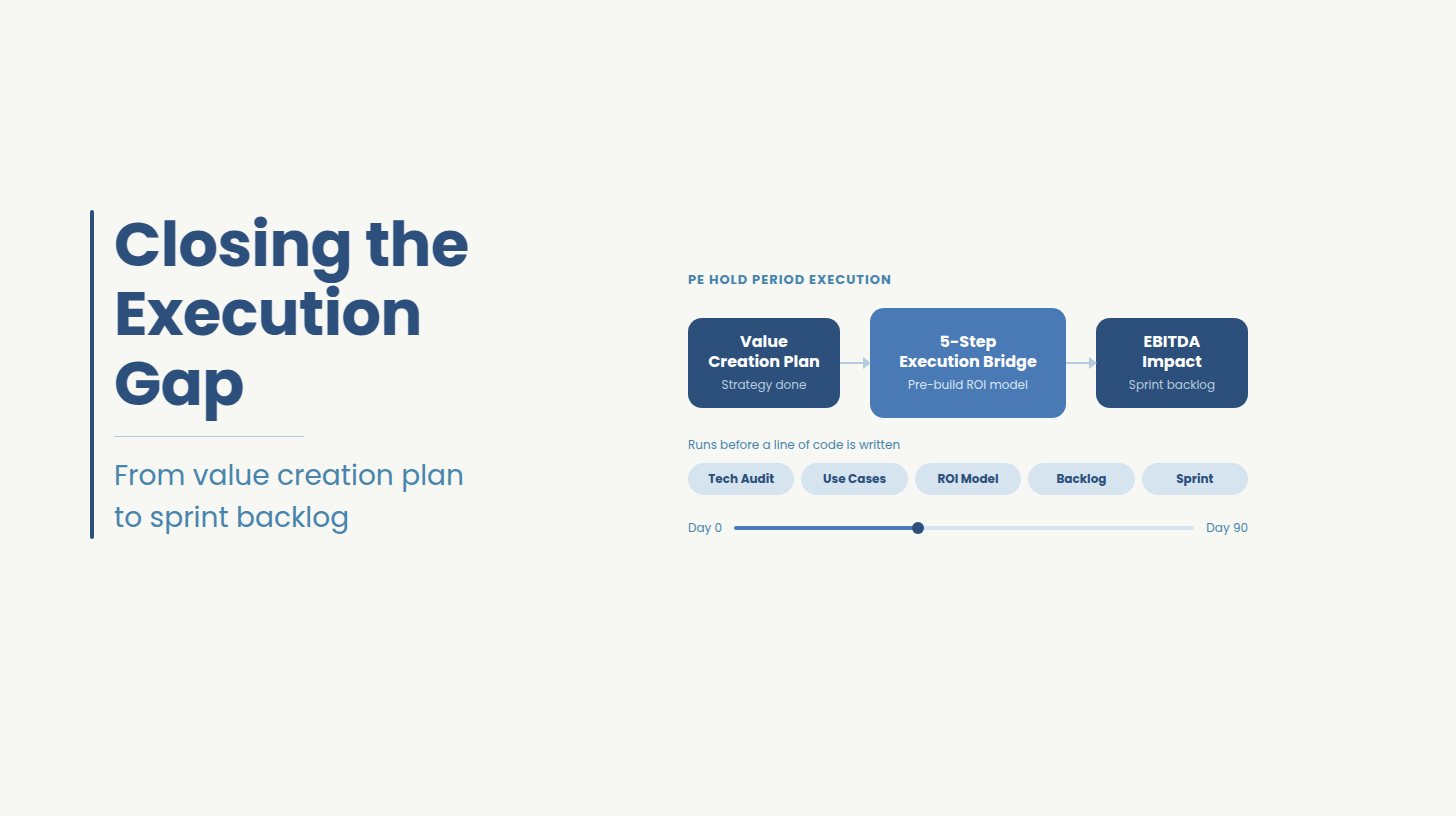
.png)
For over a decade, the cloud has been the de facto home for artificial intelligence. But recently, a new runtime is emerging. One that places AI directly on the device. Edge AI applications are gaining traction because of clear advantages: lower latency, stronger privacy, better personalization, and real-time responsiveness that cloud-dependent models can’t match.
This shift isn’t theoretical. An enterprise recently demonstrated Llama 3.2 running entirely on mobile, unlocking use cases that once seemed impossible without a server connection. Whether it’s conversational AI in cars, document summarization on smartphones, or instant visual generation in gaming, edge-native systems are proving they can deliver with far less compute and far more context-awareness.
Enterprises are following suit. Gartner predicts that by 2026, over 55% of deep learning inference will occur at the edge, up from less than 10%. As user expectations rise for AI that’s instant, personalized, and private by default, the architecture must follow. Edge AI is where the next generation of intelligent products will be born.
Read more about how edge AI is redefining intelligence delivery
The conversation around AI is not just limited to massive cloud-based models. The real breakthrough is happening on-device. The ability to run powerful language models like Llama 3.2 natively on smartphones, wearables, and even AR glasses marks a seismic shift in what’s possible at the edge.
This blog unpacks the strategic leap forward in deploying AI locally, why it matters, what makes it work, and which use cases are transforming because of it.
The earliest successes in generative AI came from large foundational models. These models delivered impressive generalist capabilities but with high latency, privacy trade-offs, and dependency on always-on connectivity.
Edge-native AI flips this model.
Thanks to advancements in model compression, contextual tuning, and hardware acceleration, enterprises can now deploy small language models (SLMs) that:
This enables new experiences where intelligence lives within the device not just in a distant cloud.
The generative AI boom began with massive, general-purpose foundation models capable of doing many things, but rarely specialized for one. These Large Language Models (LLMs) deliver impressive fluency, but demand enormous compute, memory, and bandwidth. For edge devices, this architecture is a non-starter.
That’s where Small Language Models (SLMs) come in. By fine-tuning a general model for a narrow task or training a model from scratch with limited scope, SLMs achieve efficiency, speed, and reliability. They're not trying to do everything. They're built to do one thing exceptionally well.
This specialization matters for edge AI. LLMs often hallucinate under ambiguous or open-ended prompts. In contrast, SLMs, with clearly defined context windows and task-specific training, minimize ambiguity and maximize precision, making them ideal for latency-sensitive, privacy-critical use cases.
The SLM-level implementation runs without connectivity, without external GPUs, and without degrading the user experience. Instead of cloud lookup delays, it offers real-time interactions, whether summarizing an email, responding to voice commands, or generating visuals, all on-device.
SLMs are not a step back in AI capability. They're a leap forward in deployment practicality. As product teams design for mobile, automotive, AR/VR, and IoT ecosystems, building with smaller, smarter models is becoming the only viable path to scale.
In short: they don’t try to do everything. They’re trained to do one thing extremely well.
See how optimization techniques like pruning, quantization, and fine-tuning reshape performance
From smartphones to vehicles to wearables, on-device intelligence is unlocking performance, privacy, and personalization at scale.
Here’s how edge-native applications are taking shape across verticals:
Edge-native models are changing the way people interact with their devices.
This is where agentic AI starts to feel tangible. With SLMs tied to intent recognition, these systems can orchestrate tasks rather than just respond.
Edge AI unlocks generative capabilities for creators without sacrificing speed or privacy.
This reduces dependency on cloud GPU compute while accelerating creative iteration.
Edge AI is becoming foundational to the next-gen driving experience.
These use cases demand fast, private, and context-aware AI decisions impossible to deliver consistently through the cloud alone.
Deploying AI on the edge sounds promising, but it’s architecturally demanding. Unlike cloud environments where compute is elastic and latency is abstracted, edge deployments must work within strict constraints: memory, power, thermal limits, and intermittent connectivity.
Here are the core challenges and the breakthroughs that make it possible:
On-device interactions must feel instant. That means tuning for:
Hardware acceleration (e.g., NPUs, GPUs, vector processors) is key. Llama 3.2’s ability to hit these numbers on mobile is a milestone in edge-ready inference.
Edge models can’t drain batteries. Every token, every inference, draws power.
That’s why SLMs are optimized to:
On mobile or wearable devices, this can extend battery life by hours per day compared to equivalent cloud-connected solutions.
Phones, AR glasses, and IoT devices share limited RAM between OS, apps, and AI.
SLMs must operate within 1–4GB RAM or less compared to the 20–40GB often needed by cloud LLMs.
Model sparsity, pruning, and lazy loading strategies are becoming essential tools in the edge inference stack.
Sensitive data from location to voice must stay local. Edge-native AI avoids the risk of transmission and external storage.
This enables:
Edge AI doesn’t just reduce exposure it eliminates entire risk surfaces.
In short: edge AI is hard because the engineering bar is high. But it’s worth it because the reward is real-time, secure, and hyper-personalized intelligence that cloud models simply can’t match in constrained environments
Running Llama 3.2 directly on mobile devices and glasses with no cloud dependency marks a landmark achievement in:
This unlocks:
The result: AI that’s always available, deeply personalized, and ready to act.
Building for the edge requires a fundamentally different mindset. You're not just optimizing models, you’re rethinking product flows, runtime decisions, and user expectations. Here's how engineering and product leaders should approach designing for edge-native AI:
Not every task needs to be local. Not every task should hit the cloud.
Edge-native systems should classify user intent in real time and:
This hybrid pattern ensures performance without compromising personalization or control.
Context management is critical. Instead of sending raw inputs (e.g., full documents or chat histories), edge agents should:
This reduces network usage, speeds up response time, and protects data fidelity.
Edge design means working within 4GB RAM or less, and under thermal caps.
Your models and orchestration logic must:
This is runtime-aware AI, not static inference.
Users don’t live in one device they fluidly move between phone, car, headset, and desktop.
Your edge-native system should:
This enables cohesive experiences without the lock-in or friction of centralized orchestration.
The rise of Edge AI applications marks a permanent shift in how generative systems are built, deployed, and experienced. It’s not a replacement for cloud AI but a parallel execution layer that makes products more responsive, private, and personal.
From Llama 3.2 running on mobile to SLMs embedded in vehicles, AR glasses, and smartphones, the runtime is changing. Models are embedded, and experiences are locally generated.
The next wave belongs to product teams who can translate these capabilities into edge-native intelligence intentionally designed for real-world use, across real-world constraints.
Ready to modernize your AI stack with edge-native intelligence? Explore our AI Consulting Services
Didn't find what you were looking for?