.avif)

Deep neural networks (DNN) are becoming increasingly sophisticated especially in areas like computer vision, natural language understanding, and speech recognition. With the fast maturity of DNN platforms, availability of data, and computing, DNNs are going to be increasingly prevalent.
In an era where deep learning models are becoming increasingly integral to various applications, understanding how these models make predictions is more crucial than ever. This blog explores model interpretability, a vital aspect that enables developers and stakeholders to comprehend, trust, and effectively utilize complex neural networks. We will delve into the best practices for achieving interpretability, the future trends shaping this field, and the three distinct levels of model interpretability using Captum, a powerful library designed for this purpose.
Additionally, we’ll compare Captum with other interpretability libraries to highlight its unique strengths and capabilities. Whether you’re a seasoned data scientist or new to the field, this guide will equip you with the insights needed to navigate the landscape of model interpretability effectively.
Since Neural Networks involve passing the data through multiple layers of non-linear transformations, it is impossible for a human to follow or understand the logic behind the predictions. But it is necessary, in a business context, to understand how the prediction works eg. to avoid racial bias or discrimination. It is also necessary to avoid typical pitfalls with DNNs like adversarial examples in classification and mode collapse in generative modeling. The Research Paper mentions such examples - https://arxiv.org/ftp/arxiv/papers/1903/1903.07282.pdf
Model interpretability refers to the degree to which a human can understand the reasons behind a model's predictions. In the context of machine learning and deep learning, it involves making the workings of complex models transparent and comprehensible. Interpretability is crucial for ensuring trust, accountability, and ethical considerations in AI systems, especially in sensitive applications such as healthcare, finance, and law.
Model Interpretability is an area of paramount importance for Deep Neural Networks since these models can achieve high accuracy but at the expense of high abstraction (i.e. accuracy vs interpretability problem). But this does not necessarily make the model trustworthy. A model that cannot be trusted will not be used by practitioners in their field.
By interpretation we mean functional understanding as well as the inner workings or algorithmic understanding, and captum helps us understand along these lines.
Model interpretability is vital across various domains, empowering organizations to harness the full potential of machine learning effectively. Here are several key ways it is utilized:
By analyzing model outputs, organizations can uncover biases or discriminatory behaviors in decision-making processes. This understanding is crucial for ensuring fair outcomes and mitigating the risk of perpetuating unfair biases.
Interpretability provides valuable insights into the significance and impact of various features. This knowledge can inform model refinements, data adjustments, and feature prioritization, ultimately enhancing overall performance.
Interpretability enhances communication among data scientists, domain experts, and stakeholders without technical backgrounds. Clear explanations and accessible insights promote collaboration and enable informed decision-making based on model predictions.
Model interpretability fosters transparency by allowing stakeholders to understand how decisions are made and which factors influence predictions. This openness builds trust in the model's reliability and helps validate its accuracy.
In regulated industries, model interpretability is essential for meeting legal and ethical requirements. Interpretable models facilitate easier auditing and accountability, ensuring organizations adhere to necessary standards.
By effectively leveraging model interpretability, organizations can maximize the value of their machine learning models, enhance decision-making processes, and mitigate risks associated with misunderstood or misrepresented predictions.
The future of machine learning interpretability is poised to emphasize model-agnostic tools, which provide flexibility and scalability by being decoupled from specific models. This modularity allows for easy replacement of models and interpretation methods, making model-agnostic approaches likely to dominate in the long term. While intrinsic interpretability will still hold value, automation will significantly advance both machine learning and interpretability processes.
The emphasis is moving from raw data analysis to model analysis, prioritizing the insights generated by models over the underlying data itself. Interpretable machine learning serves as a bridge to extract valuable knowledge from complex models.
The future will demand more intuitive interfaces that allow machines to provide clear explanations for their actions, improving user trust and understanding.
Data science roles may evolve as automation takes over routine tasks, with future tools streamlining many analysis and prediction processes.
Enhancing interpretability could lead to deeper insights into intelligence itself, potentially advancing the field of machine intelligence.
While the landscape of machine learning interpretability is rapidly evolving, it is essential to remain engaged with these developments and continue learning about their implications.
One of the limitations of DNNs is that they are a black box and difficult to interpret. Since Neural Networks involve passing the data through multiple layers of non-linear transformations, it is impossible for a human to follow or understand the logic behind the predictions. But it is necessary, in a business context to understand how the prediction works, eg., to avoid racial bias or discrimination. It is also necessary to avoid typical pitfalls with DNNs like adversarial examples in classification and mode collapse in generative modeling. The Research Paper mentions such examples - https://arxiv.org/ftp/arxiv/papers/1903/1903.07282.pdf
Model Interpretability is an area of paramount importance for Deep Neural Networks since these models can achieve high accuracy but at the expense of high abstraction (i.e. accuracy vs interpretability problem). But this does not necessarily make the model trustworthy. A model that cannot be trusted will not be used by practitioners in their field.
By interpretation, we mean functional understanding as well as the inner workings, or algorithmic understanding, and captum helps us understand on these lines.
Captum is an open-source, extensible library for model interpretability built on PyTorch.Here we share a technique for interpreting models by using Captum. Captum can be applied to interpret Deep Learning models built using PyTorch only.
Model Interpretability using Captum can be done at 3 different levels:
1. Primary Attribution:
It evaluates the contribution of each input feature to the output of the model. Primary Attribution makes use of Algorithms like Integrated Gradients and Deep Shifts for model interpretation.
2. Layer Attribution:
It evaluates the contribution of each neuron in a given layer to the output of the model. Layer Attribution makes use of Algorithms as Layer Conductance and Layer Gradients for layer-level model interpretation.
3. Neuron Attribution:
It evaluates the contribution of each input feature to the activation of a particular hidden neuron. Neuron Attribution makes use of Algorithms such as Neuron Conductance and Neuron Gradients for a Neuron Level Attribution.
In this blog, we will demonstrate how to interpret the models at all the 3 levels using a case study.
For this article, we have sourced a dataset from PIMA Indian Diabetes database, to predict the chances of Indian women developing diabetes using PyTorch. We have built a Feed-Forward Neural Networks Model using the PyTorch Framework for the prediction.
The dataset sample looks like below
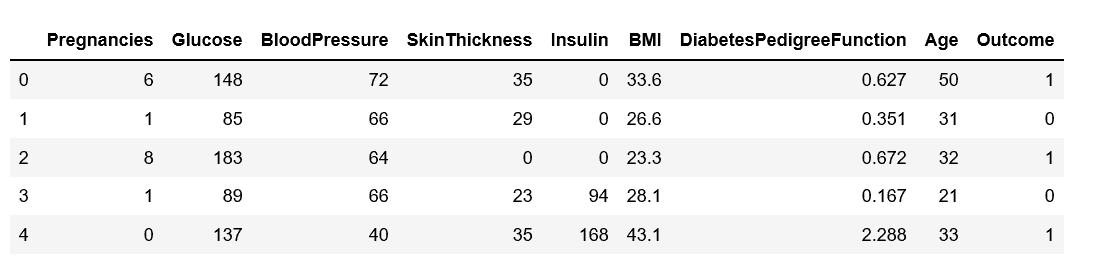
Sample dataset for the onset of diabetes in Indian women
The Dataset contains 768 observations and 8 independent features. The dataset is split into 70:30 training and testing data respectively:
The features used as an input to the model were :
DiabetesPedigreeFunction - Diabetes pedigree function (a function that scores the likelihood of diabetes based on family history)
The dependent variable or outcome is to predict whether a patient can develop diabetes. There are only two classes in the variable(Yes - 1 /No - 0).
We have defined the Neural Network Architecture as below:
A feed-forward Neural Network with 4 layers - one input layer, two hidden layers and an output layer. At the end of each layer, a sigmoid activation function is applied. In the output layer, a softmax classifier is applied.
The Neural Network Architecture for Diabetes Prediction

The Neural Network architecture is coded as below:

The model was then made to run on 200 epochs, the output of which is shown below:
The Accuracy of the model on the Testing dataset is 67% as shown below:

After the Training and Testing data split, for the model to predict on the test data, it needs to be converted into a tensor-ready format. Hence, we converted the testing features to testing tensors.
Now that we have built the model, the next step in the process is to understand how the Neural Networks can be more interpretable. Hence, we look at the attributions of the Neural Networks that we have built.
There are 3 attributions, as mentioned earlier: Primary, Feature and Neuron Attribution.
The first main component of Captum is understanding the Primary attributions. It evaluates the contribution of each input feature to the output of the model For this purpose, we apply Integrated Gradients Algorithm to arrive at the primary attributions.
In the code snippet below, we apply the Integrated Gradients Algorithm to arrive at the important attributes at the feature level and visualize the output.


Visualization of the Output:
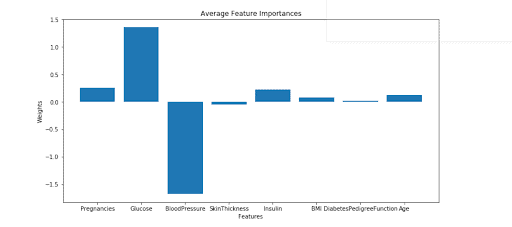
Thus, from the plot above, we infer that Blood Pressure and Glucose were the major contributors to the diabetes prediction. The positive values in the weight imply that the higher the value of the Glucose level, the more are the chances of Diabetes occurrence. The negative value of the Blood Pressure implies that if the BP level drops, there are higher chances of Diabetes Prevalence.
Layer attributions allow us to understand the importance of all the neurons in the output of a particular layer.
To use Layer Conductance, we create a LayerConductance object, passing in the model as well as the module (layer) whose output we would like to understand. In this case, we choose the output of the first hidden layer.
Code:
The code below is used to implement the Layer Conductance Algorithm at the First Hidden Layer Level (net.sigmoid 1 is the output of the hidden layer) and visualize the output.
Output:

We can infer from the above plot that Neuron 3 learns substantial features. Neurons 0 and 2 are almost similar in terms of their ability to interpret substantial features.
This allows us to understand what parts of the input contribute to activating a particular input neuron. For this example, we will apply Neuron Conductance, which divides the neuron's total conductance value into the contribution from each individual input feature.
To use Neuron Conductance, we create a NeuronConductance object, analogously to Conductance, passing in the model as well as the module (layer) whose output we would like to understand, in this case, the output of the first hidden layer, as before.
Code for interpreting Neuron 0:
The code snippet below is on the application of the Neuron Conductance Algorithm to interpret Neuron 0’s weights and attribution on the first hidden layer.


Visualization Output:

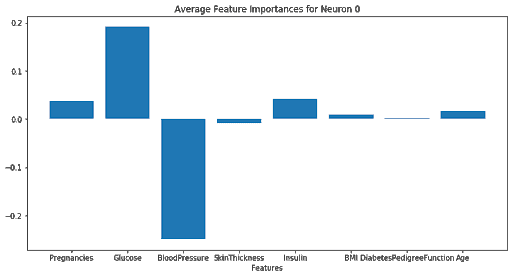
From the data above, it appears that the primary input features used by neuron 0 are Blood Pressure and Glucose, with limited importance for all other features.
Code for interpreting Neuron 3:
The code snippet below is on the application of the Neuron Conductance Algorithm to interpret Neuron 3’’s weights and attribution on the first hidden layer

Visualization Output:


Both of these neurons (0 and 3) learn substantial features from the model, such as glucose and Blood Pressure.
In this blog, we used a Healthcare AI use case to demonstrate how to interpret Neural Networks Models using Captum PyTorch Models. Model Interpretability is an area of research and currently, Captum supports only PyTorch Models. Complex Neural Networks can now be interpreted using this library. Once the Model Interpretability Analysis is done, if the attributions don’t explain the feature importance - the architecture can be changed - The number of Neurons for a layer in the existing architecture can be changed or new layers can be added and the Model Interpretability Analysis can be done.
Model interpretability is an essential pillar of responsible AI development, especially as deep learning continues to permeate various industries. Understanding how models make predictions is not just about enhancing accuracy; it’s about fostering trust, accountability, and ethical use of technology. By employing tools like Captum, practitioners can navigate the complexities of model behavior, identify biases, and improve collaboration across teams. Embrace this journey of exploration and understanding, as it is vital for harnessing the full potential of AI in a responsible and impactful manner.