IntroductionA lot of valuable insights are logged in enterprises' huge corpus of documents. Retrieving the right insight for the right context is extremely important in unlocking this value. For instance, getting answers to a question posted via a chatbot greatly depends on unlocking the answer from the appropriate document.Commonly applied full-text search often doesn’t return compelling answers. In this blog, we will explore Natural Language Processing based Answering System for information retrieval.It can be achieved through both supervised and unsupervised techniques. What we have created is an Unsupervised Information Retrieval System, DocSearch which can be integrated into a chatbot as a service where the user can get information through natural queries.
Docsearch system is a software-based framework designed to retrieve relevant information efficiently and effectively from a collection of data or documents in response to user queries.
These systems are integral to various applications, such as search engines, recommendation systems, document management systems, and chatbots. The primary goal of a Docsearch system is to bridge the gap between the user’s information needs and the available data by providing timely and accurate results.
Unlike simple keyword-based searches, modern Docsearch systems employ advanced techniques from fields like Natural Language Processing (NLP), machine learning, and data mining to understand user intent, context, and the semantics of queries and documents. This enables them to retrieve documents that match the exact keyword and answer the user’s query.
Docsearch, powered by advanced natural language processing (NLP), offers a streamlined approach to finding relevant information from vast document repositories. Here’s a look at the information retrieval process using Docsearch.
The first step involves collecting and ingesting documents into the system. Docsearch supports various formats, ensuring that all relevant data sources are included. This foundational stage is critical for building a comprehensive search index.
Once documents are ingested, Docsearch processes and indexes the content. This involves parsing the text, extracting keywords, and creating an efficient structure that allows for quick retrieval. The indexing process enhances search speed and relevance.
When a user submits a query, Docsearch utilizes NLP techniques to understand the intent behind the question. This step involves tokenization, stemming, and identifying key phrases to accurately interpret the user’s request.
After processing the query, Docsearch retrieves relevant documents from the indexed database. It ranks the results based on various factors, including keyword relevance, context, and document quality, ensuring that users receive the most pertinent information.
Once the relevant documents are identified, Docsearch formulates a response. This may include snippets from the documents, direct answers to questions, or links to full documents, depending on the user’s needs.
To enhance the accuracy and relevance of future searches, Docsearch can incorporate user feedback. This iterative process allows the system to learn from interactions and continuously improve its performance over time.
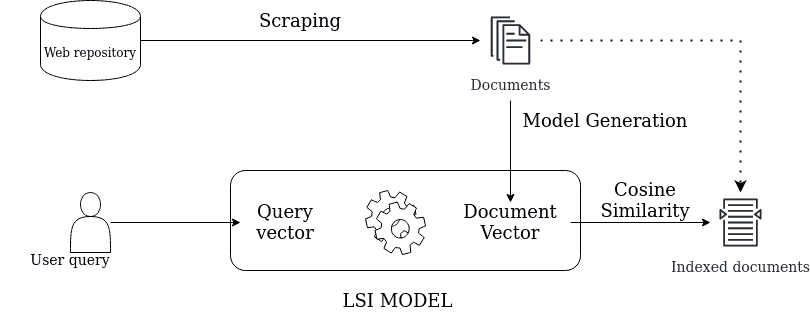
The data can be from multiple sources like web repository, PDF, word or text documents. All the documents are scraped, preprocessed and collated into a corpus in S3, which acts as a single source of information for model creation.
We used Latent Semantic Indexing (LSI) to find and rank the documents. LSI model is one of the Information retrieval methods. It is based on the Distributional hypothesis ie., words that occur in the same contexts and tend to have a similar meaning. It helps in producing concepts related to the documents. We can use this to find similarities in the documents.
Create a matrix of term frequency in respective documents, representing the number of times the term appears in the document. The matrix is large and sparse.
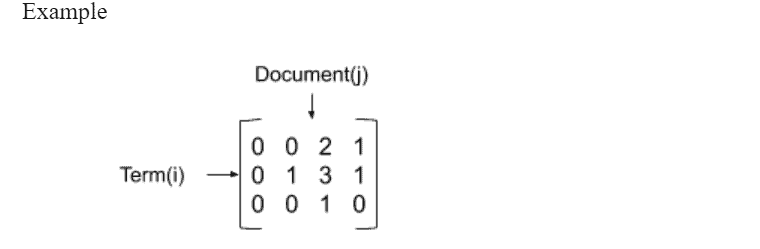
Each cell represents the frequency of term i in document j.

The Document-Topic matrix(Dk) which creates a document vector space, helps us in finding the documents relevant to the query.
Qk = qTTk-1
Whenever a new document is uploaded the model will be updated with the new documents and the entire flow has been automated.
In the world of Natural Language Processing, DocSearch stands out by revolutionizing how we interact with vast data repositories. By seamlessly connecting user queries to relevant information, it enhances the efficiency and accuracy of data retrieval.
As AI continues to evolve, grasping the interplay between Information Retrieval and Natural Language Understanding becomes essential for harnessing the full potential of intelligent answering systems. Embracing solutions like DocSearch is vital for navigating the complexities of modern information landscapes.