

As Data Science practices mature, the need to develop complex ML models and deploy them efficiently is becoming increasingly complex. If a Data Scientist is unable to production the ML Models built, it would mean huge opportunities lost in terms of cost to decision-making.To overcome these problems, Machine Learning Operations (MLOps) as a best practice was introduced. This blog helps you with how to achieve ML ops with AWS Sagemaker.MLOps in SageMaker can be achieved through the Console as well as the SageMaker API. We make the API call in the Jupyter Notebook. The blog explains both modes of achieving them. Please find a link to the GitHub Repository for implementing MLOps for Starters below :https://github.com/Ideas2IT/datascience-labAlright! Now let’s get started.MLOps has different phases in its process. The image below illustrates it :

Now let’s look into what each step in the MLOps process entails :1.Model Building Phase :In this phase, the Data Scientists build ML Models based on the Business Problem at hand, with varying hyper parameters. Typically, a Data Scientist would create the ML Models on a cloud-instance or an on-premise computer Instance that uses Jupyter Notebook or any other Machine Learning Tools. ML Algorithms could be written using cloud platform supported ML Libraries or making use of Programming language supported libraries like SciKit Learn in Python.2.Model Selection Phase:In this phase, now that a Data Scientist would have built different ML Models, it is now time to select the best model in terms of the Model Evaluation metrics. Based on the chosen metric, the best model to be deployed is identified.3.Model Deployment Phase :Having identified the best model, we need to deploy it to automate the ML flow process. The Deployment would usually be creating a Docker Image of the ML Model from External ML Libraries(Sci-Kit Learn/TensorFlow) or by making use of the Cloud Native ML Algorithms’ Image if external ML Libraries (Sci-Kit Learn/TensorFlow) are not used and creating an end-point on a Cloud Platform like AWS or Azure.For the purpose of this write-up, we have an improvised version of Sample Jupyter Notebook Example shared by AWS to the Developer Community. We have used the example Jupyter Notebook for Starters (https://github.com/aws/amazon-sagemaker-examples/blob/master/introduction_to_applying_machine_learning/video_game_sales/video-game-sales-xgboost.ipynb) and have modified the code present in this example to customize it to our blog specified objective. We have retained the Dataset used in the notebook.We will use the VideoGame Sales Dataset hosted by Kaggle - https://www.kaggle.com/datasets/rush4ratio/video-game-sales-with-ratings
MLOps using Jupyter Notebook:

The brief process of the MLOps inside of SageMaker is given below with code snippets for your understanding:1.Open the SageMaker Environment by logging on to AWS using your credentials and create a Jupyter Notebook Instance.2.Ensure that you have an S3 storage with the relevant bucket name and place the CSV file that you have downloaded from the Kaggle page mentioned above and upload it inside the S3 bucket created.3.Open up Jupyter Notebook and load the packages as shown below:

4. Load the Dataset and find the shape of the dataset :

There are 16719 records and 16 variables in the dataset on which we are trying to run an ML Model on.The Problem statement is to find out whether a particular game will become a hit or not.So for demonstration purpose, we have categorized the video games that have more than 2 million(number) in global sales as being declared a hit vis-a-vis the video games that sold less than 2 million(numbers) as not being a hitThe Outcome now looks like this

5. Performing pre-processing with the Target Variable and creating dummy variables for the categorical variables before it is fed into the model .

6. Splitting the dataset into 70% - 20% training and testing splits - with 10 % being the validation dataset.

7. Build XGBoost models making use of SageMaker’s native ML capabilities with varying hyperparameters of Maximum Depth being set at 3, 4, and 5 respectively. We are creating these models with different hyperparameters for the Model Selection phase. The next step would be the Model Selection Phase.

The below line of code will create a Training Job with an XGBoost of Max Depth 3

Performing the same activity with max-depth = 4 and 5.




8. This step in the process would be to identify the best model in terms of the Model Evaluation Metrics - AUC value. We thus make use of SageMaker’s Search API in the Jupyter Notebook.The Code Snippet below shows how to leverage the Search API


Now let’s have a look at which variant of the XGBoost model needs to be deployed :

From the above data frame, we see that the XGBoost Model with Max Depth = 5 has the highest Validation AUC and Training AUC. Hence we are going to use this model to deploy it in SageMaker.9. To deploy the model in SageMaker, the following code helps us do that :

10. To validate if an endpoint is created, it needs to be checked in the console.

The endpoint is thus created and we have it validated.
MLOps using the Console:
So far, we saw how to deploy an ML Model using the Jupyter Notebook. We shall now see how the MLOps process is done using the Console.We repeat steps 1 - 7 as mentioned above in the earlier sections on the MLOps Process. The Series of screenshots will help us understand the console-driven deployment methodology :Navigate to the Search Page and filter the search criteria as shown below:Please note that “sample” under the value section in the below screenshot mentions the name of the training job for the Video Games Data set.

The Search Criteria will give the following result of the trained models and the metrics associated with it.

Based on the above Model Metrics - we are going to deploy the Training Job that had a high AUC value. Hence the model that will be deployed will be an XGBModel with a maximum depth size of 5.Now that we have identified the Training job, we need to create the Model package for that training job to be deployed
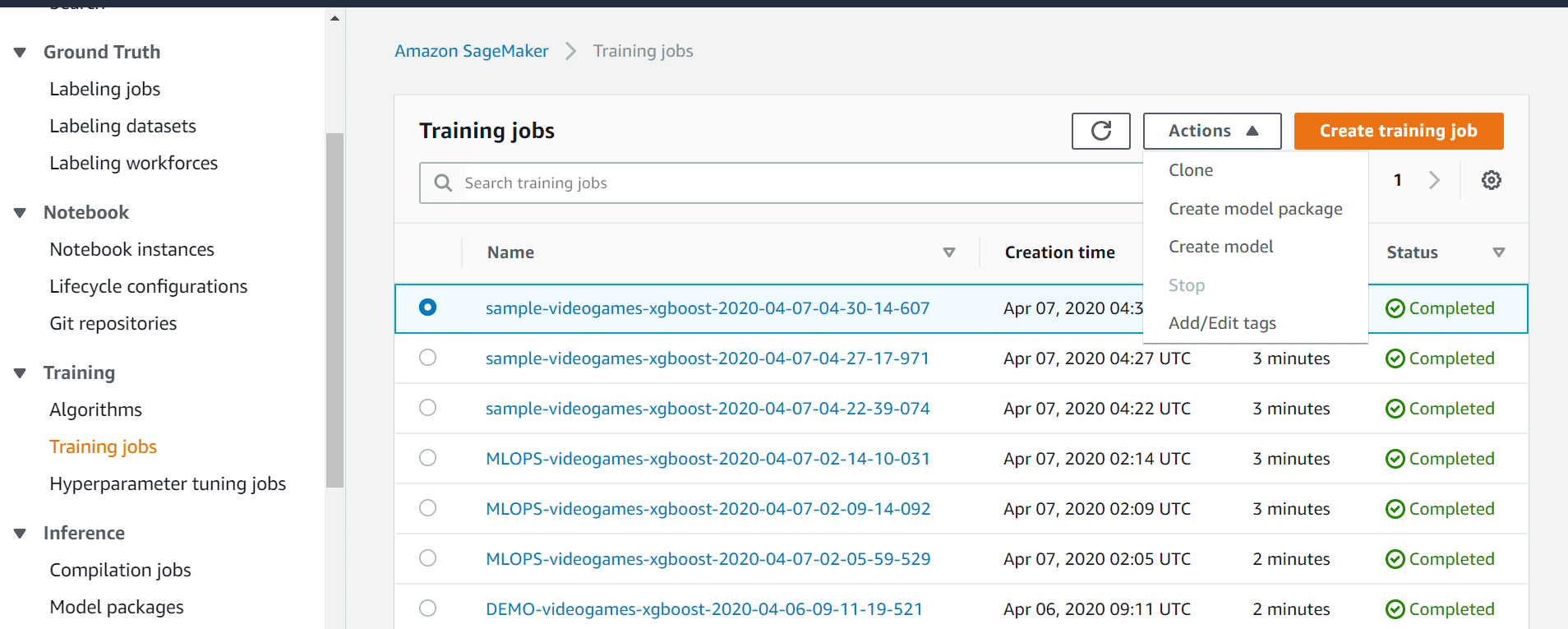

We need to create an end-point to deploy the model. Refer to the series of screenshots that follow.Navigate to the Endpoint page and click on “Create Endpoint” to initiate the process

In this page, one needs to create an End Point Name, feed in EndPoint-related configuration details, and also choose the Model that needs to be deployed.



Now that the Endpoint gets created, a success message pops up demonstrating the same.

Hurray! We have deployed our model into production. What’s the fun in only us doing it? We want you to implement the same.Happy Learning and Happy Coding! Stay tuned for more such hands-on ML Implementation Blogs.About Ideas2IT,Are you looking to build a great product or service? Do you foresee technical challenges? If you answered yes to the above questions, then you must talk to us. We are a world-class custom .NET development company. We take up projects that are in our area of expertise. We know what we are good at and more importantly what we are not. We carefully choose projects where we strongly believe that we can add value. And not just in engineering but also in terms of how well we understand the domain. Book a free consultation with us today. Let’s work together.




.png)






.avif)
.avif)

.avif)


















%20Top%20AI%20Agent%20Frameworks%20for%20Autonomous%20Workflows.avif)


%20Understanding%20the%20Role%20of%20Agentic%20AI%20in%20Healthcare.png)
%20AI%20in%20Software%20Development_%20Engineering%20Intelligence%20into%20the%20SDLC.png)
%20AI%27s%20Role%20in%20Enhancing%20Quality%20Assurance%20in%20Software%20Testing.png)

.png)






%20Tableau%20vs.%20Power%20BI_%20Which%20BI%20Tool%20is%20Best%20for%20You_.avif)
%20AI%20in%20Data%20Quality_%20Cleansing%2C%20Anomaly%20Detection%20%26%20Lineage.avif)
%20Key%20Metrics%20%26%20ROI%20Tips%20To%20Measure%20Success%20in%20Modernization%20Efforts.avif)
%20Hybrid%20Cloud%20Strategies%20for%20Modernizing%20Legacy%20Applications.avif)
%20Harnessing%20Kubernetes%20for%20App%20Modernization%20and%20Business%20Impact.avif)
%20Monolith%20to%20Microservices_%20A%20CTO_s%20Decision-Making%20Guide.avif)
%20Application%20Containerization_%20How%20To%20Streamline%20Your%20Development.avif)
%20ChatDB_%20Transforming%20How%20You%20Interact%20with%20Enterprise%20Data.avif)
%20Catalyzing%20Next-Gen%20Drug%20Discovery%20with%20Artificial%20Intelligence.avif)
%20AI%20Agents_%20Digital%20Workforce%2C%20Reimagined.avif)
%20How%20Generative%20AI%20Is%20Revolutionizing%20Customer%20Experience.avif)
%20Leading%20LLM%20Models%20Comparison_%20What%E2%80%99s%20the%20Best%20Choice%20for%20You_.avif)
%20Generative%20AI%20Strategy_%20A%20Blueprint%20for%20Business%20Success.avif)
%20Mastering%20LLM%20Optimization_%20Key%20Strategies%20for%20Enhanced%20Performance%20and%20Efficiency.avif)

.avif)





.avif)


.avif)


.avif)








































